本文面向需要为项目或团队做成本测算的开发者和负责人,讲清 Claude API 到底按什么收费、一段文字大概要花多少钱、不同规模的团队该准备多少预算,以及上线后如何监控用量、控制成本。文章给出可直接套用的换算公式和预算模板,价格数据截至 2026-06-24,以 Anthropic 官方公开定价与 claudeapi.com 控制台实时公示为准。
如果你还在纠结具体选哪个模型,可以先看《Claude API 价格与模型选择指南》,本文更侧重「钱怎么算、预算怎么定、用量怎么盯」。
这篇文章适合谁
- 准备接入 Claude API,需要先估一个月大概花多少钱的开发者。
- 要给团队或老板做预算申请、需要一份可解释口径的负责人。
- 已经上线,但账单忽高忽低、想搞清楚钱花在哪的运营或研发。
30 秒结论
- Claude API 按 Token 计费,输入、输出分开定价,输出通常是输入的 5 倍,缓存读写另有单独价位。
- 三档模型对应三档价位:Haiku(轻量高频)、Sonnet(主力甜点)、Opus(复杂任务),单价差距可达数十倍。
- 估算成本只需三步:估单次请求的输入/输出 Token → 乘以单价 → 乘以月调用量。
- 真正能压低账单的不是「选便宜模型」,而是模型分级 + Prompt Caching + 批量处理 + 控制输出长度的组合。
- 预算别一次性拉满,先按小额试跑两周拿到真实单次成本,再线性放大。
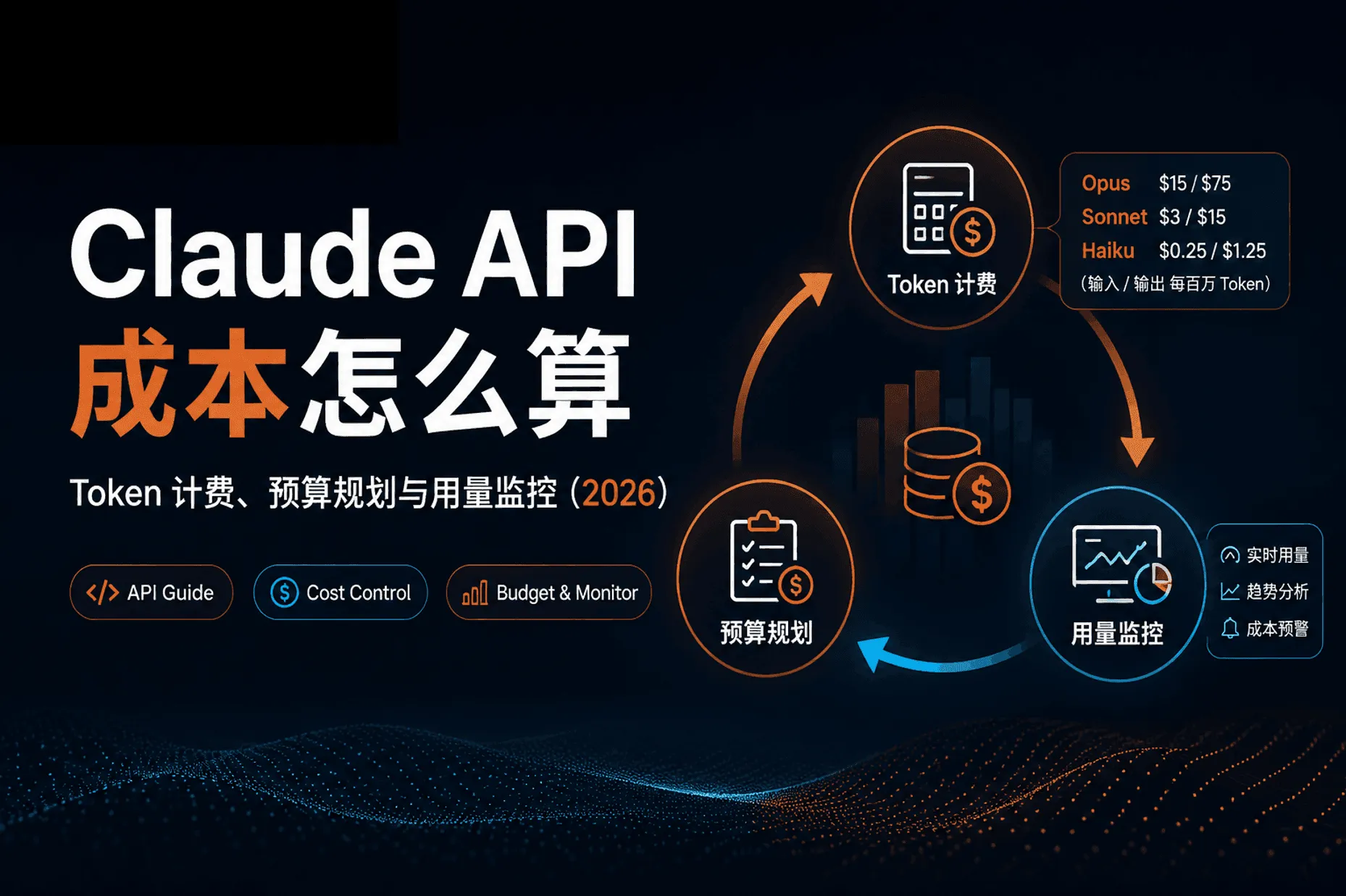
一、Claude API 按什么收费
Claude API 不按请求次数、不按时长,而是按 Token 计费。Token 是模型处理文本的最小单位。做预算时建议按偏保守的口径估算:1 个汉字约 1.5-2 个 Token,1 个英文单词约 1.2-1.3 个 Token,100 万 Token 大约能写 50-60 万个汉字。
一次请求的费用由以下几部分相加:
| 计费项 | 说明 | 相对单价 |
|---|---|---|
| 输入(Input) | 你发给模型的全部内容:系统提示、对话历史、文档、本轮问题 | 基准价 |
| 输出(Output) | 模型生成返回的内容 | 约为输入的 5 倍 |
| 缓存写入(Cache Write) | 把固定内容写入 Prompt Cache,5 分钟档 1.25×、1 小时档 2× 输入价 | 高于输入价 |
| 缓存命中(Cache Hit) | 命中缓存的输入只按 0.1× 输入价计费 | 输入价的 1/10 |
需要特别注意三点:
- 输出比输入贵得多。同样 1000 个 Token,输出花的钱大约是输入的 5 倍,所以「让模型少废话」是最直接的省钱手段。
- 对话历史会重复计费。多轮对话里,每一轮都会把之前的历史重新作为输入发送,轮次越多、历史越长,输入成本累积越快。
- 缓存是双刃剑。写入比普通输入贵,命中比普通输入便宜,只有被重复读取才划算。
二、官方定价与人民币计价
具体以 claudeapi.com 控制台实时公示为准。
公开信息显示当前最新旗舰为 Claude Opus 4.8(API 名
claude-opus-4-8,2026-05-28 上线);主力为 Sonnet 4.6,高频档为 Haiku 4.5。模型版本更替较快,配置前请核对控制台的实时模型列表。
2.1 美金口径
claudeapi.com 作为独立第三方技术服务商,美金售价为 Anthropic 官方定价的八折,无最低消费、无月费。下表左列为官方参考价,右列为 claudeapi.com 实际售价(每百万 Token):
| 模型 | 官方输入 | 官方输出 | claudeapi.com 输入 | claudeapi.com 输出 |
|---|---|---|---|---|
| Claude Opus 4.8(最新旗舰) | $5 | $25 | $4 | $20 |
| Claude Sonnet 4.6(主力) | $3 | $15 | $2.4 | $12 |
| Claude Haiku 4.5(高频) | $1 | $5 | $0.8 | $4 |
缓存写入、缓存命中等附加计费项以控制台实时公示为准。
2.2 人民币计价
claudeapi.com 作为独立第三方技术服务商,提供人民币与美金两种结算货币,选哪个币种就按哪个币种扣费,不做隐形汇率换算。人民币标准价(每百万 Token)如下:
| 模型 | 输入 | 输出 | 5 分钟缓存写入 | 1 小时缓存写入 | 缓存命中 |
|---|---|---|---|---|---|
| Claude Opus 4.8 | ¥20 | ¥100 | ¥25 | ¥40 | ¥2 |
| Claude Sonnet 4.6 | ¥4 | ¥20 | ¥5 | ¥8 | ¥0.4 |
| Claude Haiku 4.5 | ¥1 | ¥5 | ¥1.25 | ¥2 | ¥0.1 |
缓存倍率与官方口径一致:5 分钟写入 1.25×、1 小时写入 2×、命中 0.1×。
2.3 三个容易被忽略的计费细节
- 最大输出变长:Opus 4.8 单次最大输出从上一代的 64K 提升到 128K Token。输出上限变高意味着「放任模型写长」时账单上涨空间也更大,务必主动设
max_tokens。 - 1M 上下文统一定价:当前主力模型的 100 万 Token 上下文窗口多为全段统一定价,但部分旧版本(如 Sonnet 4.5)仍存在 200K 门槛溢价,老项目建议迁移到新版本。
- Web Search、Fast 模式等附加能力单独计费:内置 Web Search、Fast 模式等按各自规则计费,启用前看清单价。值得一提的是,Opus 4.8 的 Fast Mode 已从上一代的 $30 / $150 下调到 $10 / $50(每百万 Token 输入 / 输出),相对标准价的溢价从约 6 倍降到约 2 倍,提速幅度不变;对延迟敏感的场景更划算了,但仍比标准模式贵,按需启用。具体溢价规则以官方文档为准。
三、一段文字大概要花多少钱
成本估算的核心是把「字数」换成「Token」,再乘以单价。
3.1 字数与 Token 换算
做成本预算时,字数到 Token 建议按偏保守口径换算,给提示词模板、格式符号和分词差异留余量:
- 中文:1 个汉字 ≈ 1.5-2 个 Token,即 1 万汉字 ≈ 1.5 万-2 万 Token。
- 英文:1 个单词 ≈ 1.2-1.3 个 Token。
- 综合参考:100 万 Token ≈ 50-60 万个汉字。
- 估算时统一向上取整,宁可高估也不要低估预算。
3.2 1 元能买多少 Token
以人民币口径直观感受一下成本量级:
| 模型 | 1 元 ≈ 输入 Token | 1 元 ≈ 输出 Token | 一次典型问答(200 输入 / 500 输出) |
|---|---|---|---|
| Haiku 4.5 | 100 万 | 20 万 | ≈ ¥0.0027 |
| Sonnet 4.6 | 25 万 | 5 万 | ≈ ¥0.0108 |
| Opus 4.8 | 5 万 | 1 万 | ≈ ¥0.054 |
一次普通问答(输入 200 Token、输出 500 Token),用 Sonnet 大约一分钱出头,用 Haiku 不到三厘,用 Opus 约五分钱。看单次很便宜,但乘以每月几十万、上百万次调用,差距会被放大。
3.3 单次成本计算公式
单次成本 = 输入 Token / 1,000,000 × 输入单价
+ 输出 Token / 1,000,000 × 输出单价
+ 缓存写入 Token / 1,000,000 × 缓存写入单价
+ 缓存命中 Token / 1,000,000 × 缓存命中单价
单次成本 = 输入 Token / 1,000,000 × 输入单价
+ 输出 Token / 1,000,000 × 输出单价
+ 缓存写入 Token / 1,000,000 × 缓存写入单价
+ 缓存命中 Token / 1,000,000 × 缓存命中单价
举例:用 Sonnet 4.6(人民币口径,输入 ¥4 / 输出 ¥20)处理一篇文档摘要,输入 8000 Token、输出 1500 Token:
输入成本 = 8000 / 1,000,000 × 4 = ¥0.032
输出成本 = 1500 / 1,000,000 × 20 = ¥0.030
单次合计 ≈ ¥0.062
输入成本 = 8000 / 1,000,000 × 4 = ¥0.032
输出成本 = 1500 / 1,000,000 × 20 = ¥0.030
单次合计 ≈ ¥0.062
如果每天处理 2000 篇,月成本约 0.062 × 2000 × 30 ≈ ¥3720。把它换成 Haiku 做初筛、Sonnet 只处理需要深度理解的部分,账单还能再降一截。
四、按团队规模做预算
下面给出三档参考预算,基于「先小额试跑、再线性放大」的原则。实际金额取决于业务调用量,这里只提供估算框架,不构成任何收益或费用承诺。
4.1 预算估算四步法(HowTo)
步骤一:估单次 Token
跑 20-50 次真实请求,记录平均输入、输出 Token。可直接读取返回里的 usage 字段。
步骤二:算单次成本
套用第 3.3 节公式,得到单次平均成本。
步骤三:估月调用量
根据业务峰值和日活,估算每月总调用次数。
步骤四:留缓冲
在理论值上加 20%-30% 缓冲,应对重试、长对话和异常流量。
月预算 ≈ 单次平均成本 × 月调用量 × (1 + 缓冲比例)
月预算 ≈ 单次平均成本 × 月调用量 × (1 + 缓冲比例)
4.2 三档参考场景
| 团队规模 | 典型用途 | 模型搭配建议 | 月调用量级 | 预算思路 |
|---|---|---|---|---|
| 个人 / 小项目 | 个人助手、Demo、低频脚本 | Haiku 为主,Sonnet 兜底 | 数千到数万次 | 先充小额试跑,按真实账单续费 |
| 中小团队 | 客服、RAG 问答、内容生产 | Sonnet 为主,Haiku 做初筛 | 数十万次 | 用试跑数据反推月预算,加 30% 缓冲 |
| 较大业务 | 多 Agent、复杂代码、长上下文 | 三档分级,Opus 只用于关键决策 | 百万次以上 | 分模型核算,重点优化高频低价值调用 |
4.3 充值与阶梯优惠
claudeapi.com 无最低消费、无月费,支持按需充值,余额永久有效。充值页提供预设金额和自定义金额两种方式,大额充值享有阶梯折扣:
| 充值金额 | 实付金额 | 折扣 | 说明 |
|---|---|---|---|
| $10 | $10 | 无折扣 | 轻量体验 |
| $30 | $30 | 无折扣 | 个人开发 |
| $50 | $50 | 无折扣 | 日常使用 |
| $100 | $98 | -2% | 小额批量 |
| $300 | $291 | -3% | 中量生产 |
| $500 | $475 | -5% | 大额最优 |
| 自定义金额 | — | 按区间适用 | 填写任意金额 |
支持支付方式: Stripe 支付宝、Stripe 卡支付、Stripe 微信支付、Stripe 加密货币。支持人民币(CNY)和美元(USD)两种结算货币,按所选币种扣费,不做隐性汇率换算。
五、用量监控:别等账单出来才发现超支
成本失控往往不是单价问题,而是「没人盯用量」。建议从上线第一天就建立监控。
5.1 控制台自查
- 定期查看控制台的调用记录、Token 消耗和账单明细。
- 按模型拆分用量,确认是不是某个高频接口在偷偷烧 Opus。
- 关注输出 Token 占比,输出长度异常往往是账单上涨的主因。
5.2 代码侧埋点
在调用返回里读取 usage 字段,记录每次请求的输入、输出和缓存 Token,落到自己的日志或监控系统:
import anthropic
client = anthropic.Anthropic(
api_key="CLAUDE_API_KEY", # 用占位符,不要硬编码真实 Key
base_url="https://api.example.com", # 替换为你的实际 Base URL
)
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024, # 主动设上限,避免输出失控推高账单
messages=[{"role": "user", "content": "总结这段会议纪要……"}],
)
usage = resp.usage
print(f"input={usage.input_tokens}, output={usage.output_tokens}")
# 把 usage 写入日志或监控,按天/按接口聚合,超阈值告警
import anthropic
client = anthropic.Anthropic(
api_key="CLAUDE_API_KEY", # 用占位符,不要硬编码真实 Key
base_url="https://api.example.com", # 替换为你的实际 Base URL
)
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024, # 主动设上限,避免输出失控推高账单
messages=[{"role": "user", "content": "总结这段会议纪要……"}],
)
usage = resp.usage
print(f"input={usage.input_tokens}, output={usage.output_tokens}")
# 把 usage 写入日志或监控,按天/按接口聚合,超阈值告警
5.3 设预算红线
- 给每个环境(开发、测试、生产)分开记账,避免测试流量污染生产成本。
- 设置月度软上限,接近阈值时告警,而不是等余额耗尽才发现。
- 生产环境务必加重试、限流和超时控制,避免异常重试把 Token 用量翻倍。重试要用指数退避,并设置最大重试次数,防止失败请求反复扣费。
六、四个能落地的降本方法
降本的本质是「用更便宜的方式拿到同样的结果」,而不是牺牲质量。
6.1 模型分级:别什么都上 Opus
把任务按复杂度分配,是性价比最高的一招:
分类 / 抽取 / 翻译 / 路由判断 → Haiku 4.5
日常编程 / 内容创作 / RAG 问答 → Sonnet 4.6(90% 场景的甜点)
复杂重构 / 多 Agent / 深度推理 → Opus 4.8(关键决策才用)
分类 / 抽取 / 翻译 / 路由判断 → Haiku 4.5
日常编程 / 内容创作 / RAG 问答 → Sonnet 4.6(90% 场景的甜点)
复杂重构 / 多 Agent / 深度推理 → Opus 4.8(关键决策才用)
经验比例:高频轻量任务 60%-70% 走 Haiku,主要业务逻辑 20%-30% 走 Sonnet,真正复杂的 5%-10% 才用 Opus。
如果用的是 Opus 4.8,还可以借助它的 Effort Control(思考强度,分 Low 到 Max 多档)来调节成本:思考档位越高,生成的思考 Token 越多、越贵。简单任务调低档位,能在不换模型的前提下省下一部分输出成本。
6.2 Prompt Caching:固定内容命中即 0.1× 输入价
把不变的系统提示、长文档、固定示例打上缓存断点,命中后输入成本降到 1/10。适合 RAG 知识库、固定系统提示、Agent 工作流和多轮对话。5 分钟缓存被读 1 次回本,1 小时缓存读 2 次回本。具体配置见《Claude API 提示词缓存实战》。
6.3 批量处理:非实时任务走 Batch
对不要求实时返回的任务(批量摘要、离线标注、数据清洗),用 Batch 方式提交通常能拿到更低的单价。把「能等」的任务和「要快」的任务分开处理,是大批量场景的关键。详见《Claude Batch API 成本优化》。
6.4 控制输出长度:输出比输入贵 5 倍
- 提示词里写明「只返回 JSON / 不要解释 / 不超过 N 字」。
- 用结构化输出(Tool Use 或 JSON Schema)约束格式,避免模型自由发挥。
- 主动设置
max_tokens,尤其在 Opus 4.8 最大输出已达 128K 的情况下,不设上限风险更大。 - 长文档先用 Haiku 切片摘要,再喂给 Sonnet 做最终处理。
- 多轮对话定期裁剪历史,只保留最近 N 轮 + 摘要,避免历史无限增长。
七、常见问题 FAQ
Claude API 到底是按次数还是按 Token 收费?
按 Token 收费,不按请求次数。每次请求的费用 = 输入 Token × 输入单价 + 输出 Token × 输出单价,再加上可能产生的缓存读写费用。所以同样调用一次,处理长文档比短问答贵得多。
为什么我的账单里输出比输入贵那么多?
因为输出单价通常是输入的约 5 倍。如果模型回复很长,输出 Token 会迅速累积。可以在提示词里限制输出长度、使用结构化输出、主动设 max_tokens,或先用更便宜的模型做预处理来压缩成本。
多轮对话为什么越聊越贵?
每一轮请求都会把之前的对话历史重新作为输入发送,轮次越多、历史越长,重复计费的输入就越多。建议定期裁剪历史、只保留最近几轮加摘要,必要时配合 Prompt Caching 缓存固定上下文。
claudeapi.com 的人民币价格和官方美金价格是什么关系?
claudeapi.com 是独立第三方技术服务商,提供人民币与美金两种结算货币,选哪个币种按哪个币种扣费,不做隐形汇率换算。具体价格以充值页和控制台实时展示为准。
怎么先估一个月大概花多少钱?
先跑 20-50 次真实请求,记录平均输入、输出 Token,套用单次成本公式得到单次平均成本,再乘以预估月调用量,最后加 20%-30% 缓冲。建议先充小额试跑两周,拿到真实账单后再线性放大预算。
用了最新的 Opus 4.8,成本会比上一代高吗?
按公开信息,Opus 4.8 标准版输入/输出单价与上一代 Opus 一致,单价层面没有上涨。但它最大输出提升到 128K Token,如果不设 max_tokens、放任长输出,单次输出成本可能更高;同时它的思考强度档位越高,思考 Token 越多。控制好输出长度和思考档位,成本可控。
余额会过期吗?充值后多久能用?
按 claudeapi.com 公开说明,账户余额按 Token 实际消耗扣减,充值通常实时到账。具体到账时间、余额有效期和发票规则以平台实际规则和控制台展示为准。
八、下一步
如果你已经算清成本,下一步可以:
- 还没有 Key?先看《Claude API Key 获取指南》,拿到 Key 才能跑试算。
- 拿不准选哪个模型?参考《Claude API 价格与模型选择指南》做分级。
- 想看更细的计费拆解?阅读《Claude API 价格完全指南:多少钱?怎么算?怎么省?》。
- 想进一步压成本?阅读《Claude API 提示词缓存实战》和《Claude Batch API 成本优化》。


