Anthropic 在 2026 年 6 月 30 日发布 Claude Sonnet 5。对 API 用户来说,这不是一次简单的模型名更新,而是 Sonnet 这一主力模型线在上下文窗口、输出能力、Agent 工作流和代码任务上的一次重要升级。
如果你正在使用 Claude Code、Cursor、Cline、Open WebUI、LibreChat、Dify,或者在自研系统中接入 Claude API,Sonnet 5 最先需要确认的不是“效果是不是更强”,而是四个更基础的问题:模型 ID 是否可用、价格口径是否清楚、上下文策略是否要调整、现有客户端是否支持切换。
一句话结论
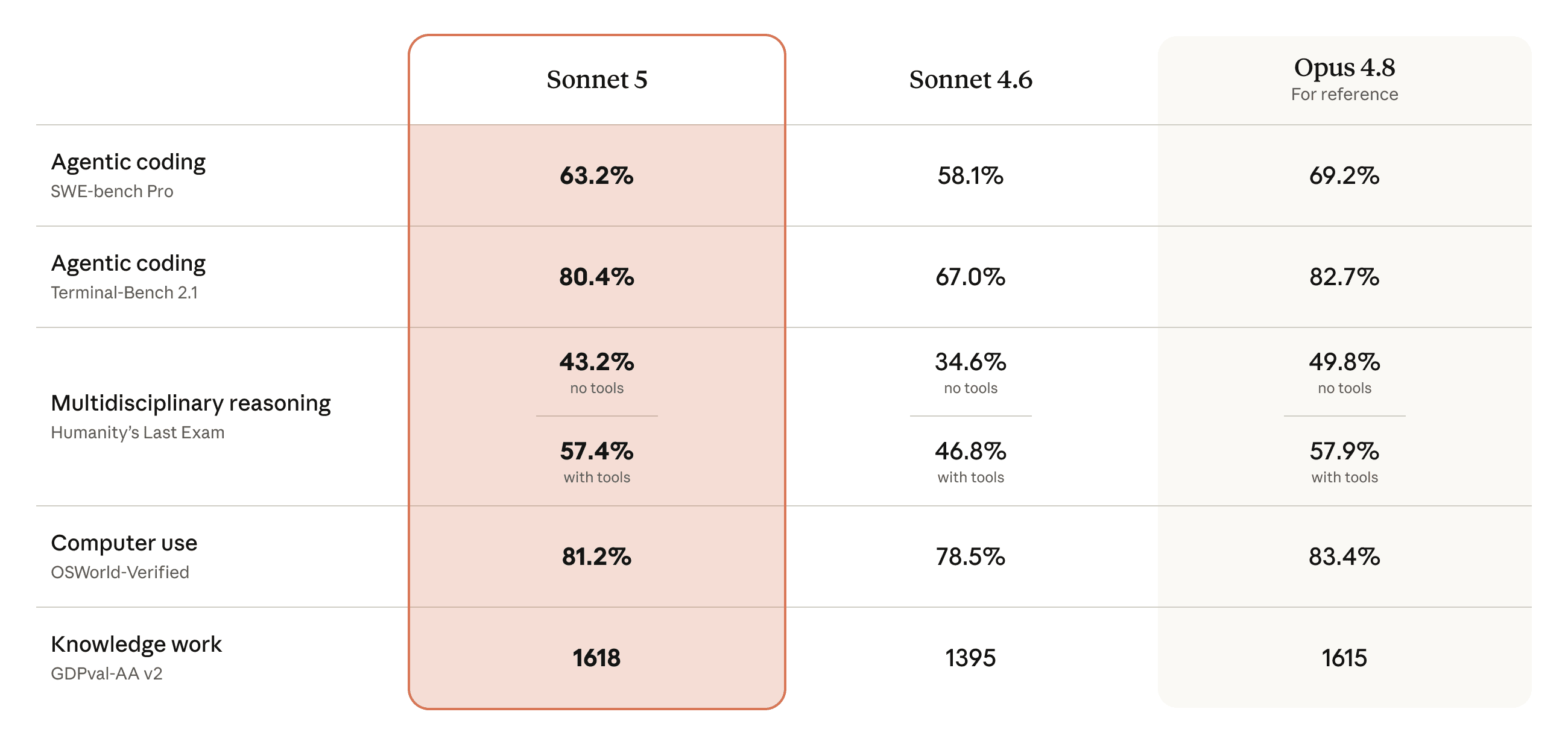
Claude Sonnet 5 的 API model ID 是 claude-sonnet-5。它支持 1M token context window、128k max output tokens。当前价格为:输入 $1.600/M tokens、输出 $8.000/M tokens;输入缓存 $0.160/M tokens、输出缓存 $2.000/M tokens。官方公开参考价为输入 $2.000/M tokens、输出 $10.000/M tokens。
对多数团队来说,Sonnet 5 更适合作为“复杂任务主力模型”,而不是把所有轻量请求都直接替换过去。更稳的做法是:复杂代码、长文档、Agent、多步骤分析先测 Sonnet 5;简单分类、短摘要、固定格式抽取继续用低成本模型。
关键参数速览
| 项目 | 信息 |
|---|---|
| 发布时间 | 2026-06-30 |
| API model ID | claude-sonnet-5 |
| 上下文窗口 | 1M tokens |
| 最大输出 | 128k tokens |
| ClaudeAPI 输入价格 | $1.600 / MTok |
| ClaudeAPI 输出价格 | $8.000 / MTok |
| ClaudeAPI 输入缓存 | $0.160 / MTok |
| ClaudeAPI 输出缓存 | $2.000 / MTok |
| 官方公开参考价 | $2.000 / MTok input,$10.000 / MTok output |
| Prompt caching | 官方说明最高可节省 90% |
| Batch processing | 官方说明可节省 50% |
| Priority Tier | release notes 显示 Sonnet 5 暂不支持 Priority Tier |
以上价格为 2026-07-01 核对口径。实际使用时,请以 ClaudeAPI 控制台和价格页展示为准,尤其是模型可用状态、缓存计费、余额扣费、并发和限额策略。
Sonnet 5 的定位:主力模型,而不是最低成本模型
Sonnet 系列一直更接近“日常主力模型”:比轻量模型更适合复杂推理、代码、长文档和 Agent,比顶级旗舰模型更适合规模化调用。Sonnet 5 延续了这个定位。
这意味着它最适合解决三类问题。
第一类是复杂代码任务。Claude Code、Cline、Cursor 这类工具不会只发起一次请求,而是会连续读取文件、分析错误、修改代码、执行测试、根据反馈继续修复。模型需要在多轮工具调用中保持任务状态,Sonnet 5 的长上下文和代码能力更适合这类链路。
第二类是长文档和知识工作。1M context 的价值不是“把所有资料都塞进去”,而是减少切片带来的信息损失。合同、研报、技术方案、知识库重组、项目迁移文档,都可能从更完整的上下文中受益。
第三类是需要较长输出的结构化任务。128k max output 可以让模型一次生成更完整的方案、文档、测试用例或迁移计划。但输出越长,成本和人工复核压力越高,因此仍然要按任务设置 max_tokens。
为什么不能直接全量切换
新模型上线后,最容易出现的误区是:既然更强,就把所有任务都切过去。这个做法通常会带来两个问题。
一是账单不可控。Sonnet 5 的单价不是唯一变量,真正影响成本的是上下文长度、输出长度、重试次数、Agent 循环轮次和缓存命中率。一个简单任务如果被包装成多轮 Agent 调用,成本可能远高于预期。
二是任务收益不均衡。复杂代码任务可能明显受益,简单分类任务未必有必要升级。模型升级的核心不是“追最新”,而是让模型能力和任务价值匹配。
可以按下面这张表做初步判断:
| 任务类型 | 是否建议优先测试 Sonnet 5 | 原因 |
|---|---|---|
| Claude Code / Cline / Cursor 多文件修改 | 建议优先测试 | 长上下文和工具调用收益明显 |
| 复杂 bug 排查、架构迁移、代码审查 | 建议测试 | 需要跨文件理解和多步推理 |
| 长文档分析、知识库整理、批量内容生产 | 建议测试 | 1M context 能减少切片损失 |
| 内部 Agent、多步骤自动化任务 | 建议测试但要设预算 | 能力收益高,成本风险也高 |
| 简单分类、短摘要、格式转换 | 不建议优先迁移 | 低成本模型通常足够 |
| 高频客服寒暄、固定模板回复 | 谨慎使用 | 调用量大,边际收益有限 |
接入前的 6 项检查
1. 检查模型 ID
Sonnet 5 的模型 ID 是:
claude-sonnet-5
claude-sonnet-5
不要把 sonnet、latest、claude-3-5-sonnet、default 等宽泛名称当成 Sonnet 5。中间层、网关和客户端可能有自己的模型映射,发布前应在控制台确认。
2. 检查价格和缓存口径
ClaudeAPI 当前核对价格为:
| 计费项 | 价格 |
|---|---|
| 输入 | $1.600 / MTok |
| 输出 | $8.000 / MTok |
| 输入缓存 | $0.160 / MTok |
| 输出缓存 | $2.000 / MTok |
如果你的任务有大量重复系统提示词、长文档模板、固定知识库片段,应优先评估 prompt caching。对内容批量生成、离线报告、知识库重建等非实时任务,可以评估 Batch 或异步队列,把实时请求和离线请求分开。
3. 检查上下文策略
1M context 不等于每次请求都应该塞满 1M。建议按任务分层:
| 任务 | 推荐上下文策略 |
|---|---|
| 单文件代码修复 | 只传相关文件、错误日志和复现步骤 |
| 多文件重构 | 传目录结构、关键文件、接口约束和变更目标 |
| 长文档问答 | 先做章节索引,再传关键章节 |
| 合同 / 研报分析 | 可利用长上下文,但要求分章节输出 |
| Agent 自动任务 | 设置最大轮次、最大 token、工具白名单和预算 |
4. 检查客户端兼容
不同工具支持新模型的节奏不一定一致。建议重点检查:
model字段是否允许填写claude-sonnet-5max_tokens是否支持更高输出- streaming 是否稳定
- tool use / function calling 是否被透传
- OpenAI 兼容层是否有模型白名单
- 日志中是否能记录 input / output tokens
如果报错 model not found,优先检查控制台是否已上线、Base URL 是否正确、SDK 是否过旧、网关是否限制模型列表。
5. 检查预算和日志
生产环境不建议只记录总费用。至少要记录:
| 字段 | 用途 |
|---|---|
| model | 判断哪些任务在用 Sonnet 5 |
| task_type | 区分代码、文档、分类、Agent 等任务 |
| input_tokens / output_tokens | 分析成本来源 |
| latency_ms | 分析响应速度 |
| retry_count | 发现失败重试导致的额外成本 |
| cache_read / cache_write | 判断缓存是否真正命中 |
| user_id / project_id | 做团队和项目级预算 |
只有这些日志字段齐全,后续才能判断 Sonnet 5 是提升了质量,还是只是提高了单次消耗。
6. 做真实任务 A/B 测试
建议选 10-20 条真实任务,不要只用演示 prompt。对比维度包括:输出质量、人工修改量、token 消耗、耗时、重试次数、失败率。尤其是 Claude Code、Cline、Cursor 用户,最好拿真实项目测试,因为 Sonnet 5 的价值往往体现在多文件、长链路、复杂修复中。
ClaudeAPI 用户推荐迁移路径
- 在控制台确认
claude-sonnet-5是否可选。 - 记录当前价格、缓存、限额、并发口径。
- 新建测试 Key 或测试环境,不直接改生产配置。
- 抽取真实任务做 A/B 测试。
- 为 Agent 类任务设置最大轮次、最大 token 和预算上限。
- 将收益明显的任务切到 Sonnet 5,将简单任务保留在低成本模型。
- 持续观察日志,按任务类型调整模型路由。
一个更成熟的模型路由可以是:
| 任务 | 推荐模型思路 |
|---|---|
| 高频简单问答 | 低成本模型 |
| 标准写作、摘要、日常分析 | Sonnet 4.6 或 Sonnet 5 视成本测试决定 |
| 复杂代码、长上下文、Agent | 优先测试 Sonnet 5 |
| 极高价值深度推理 | 再考虑更高阶模型 |
 |
常见误区
误区一:1M context 可以替代所有 RAG。
长上下文能减少切片,但不等于 RAG 不再需要。大规模知识库、权限隔离、增量更新、可追溯引用,仍然适合用检索系统解决。
误区二:128k 输出应该默认开到最大。
输出上限是能力,不是默认配置。业务里应按任务设置合理的 max_tokens,否则长输出会带来更高成本和更重审核压力。
误区三:新模型上线就应该替换旧模型。
模型升级应该看任务收益。简单任务继续用低成本模型,复杂任务使用更强模型,才是更稳定的成本结构。
误区四:只看单价,不看调用链路。
Agent、自动重试、长上下文、长输出、工具调用都会放大成本。上线前必须配套日志、预算、限流和 fallback。
参考来源
- Anthropic Sonnet 页面:https://www.anthropic.com/claude/sonnet
- Claude API Release Notes:https://platform.claude.com/docs/en/release-notes/overview
- Claude Pricing:https://docs.anthropic.com/en/docs/about-claude/pricing
- Claude Models Overview:https://platform.claude.com/docs/en/about-claude/models/overview
结论
Claude Sonnet 5 是一次值得 API 用户认真评估的主力模型更新。它的价值集中在复杂代码、长上下文、长输出和 Agent 工作流上;它的风险也很明确:如果没有预算、日志和任务分层,成本可能比预期增长更快。
对 ClaudeAPI 用户来说,最稳的做法不是全量切换,而是先确认模型 ID 和价格口径,再用真实任务测试,把 Sonnet 5 放到真正需要它的场景里。复杂任务用强模型,简单任务控成本,长任务配合缓存和预算上限,这才是 Sonnet 5 上线后的合理使用方式。