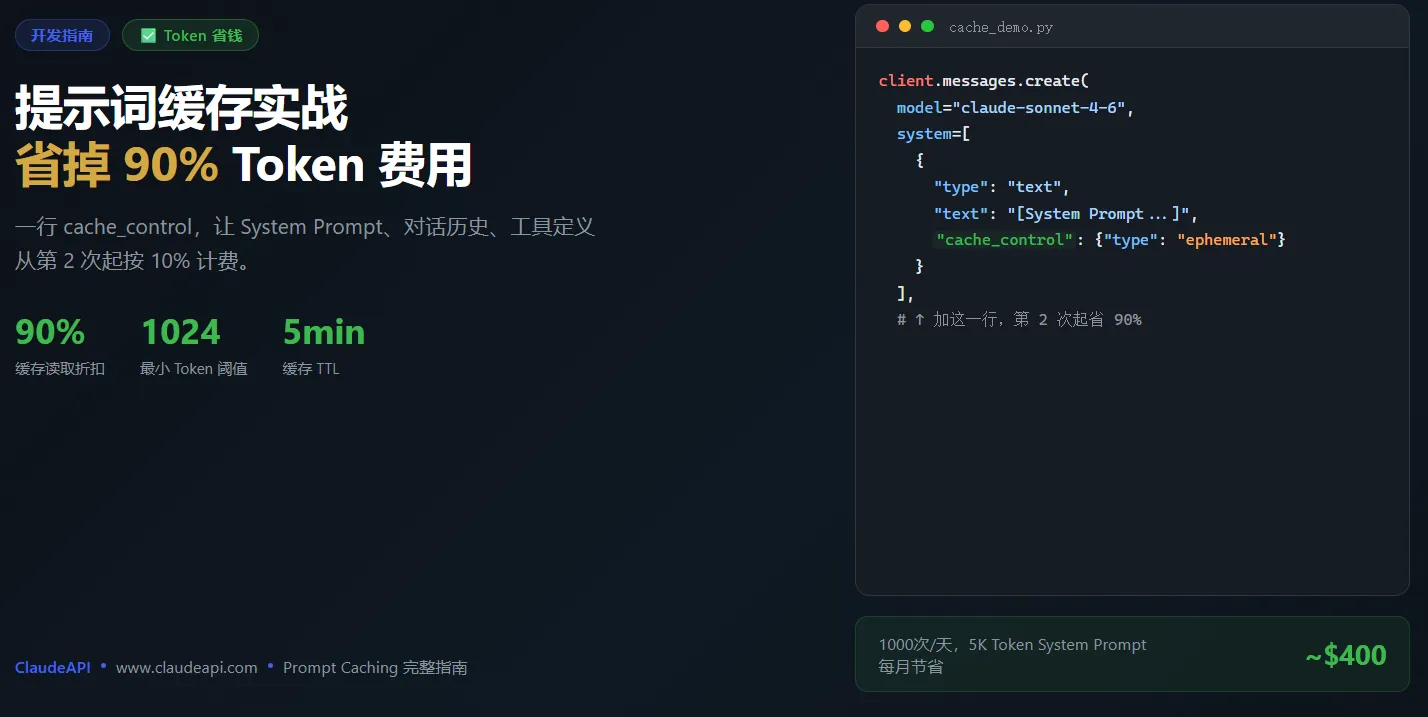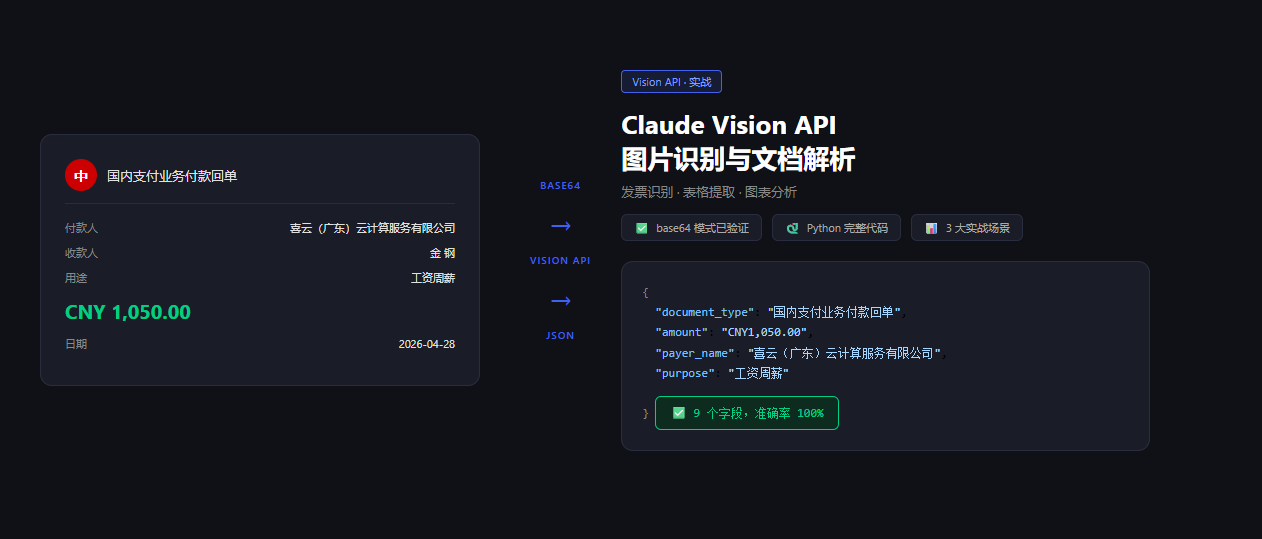
Claude Vision API 实战:图片识别与文档解析完全指南
每月手动录入几十张发票、把扫描版合同里的表格重新打一遍、盯着报表截图提炼数据趋势……
这些繁琐的图片信息提取工作,Claude Vision API 可以一键搞定。
Claude 的视觉能力允许你把图片直接传给模型——不管是银行回单、数据表格还是折线图,一次 API 调用就能拿到结构化结果。本文基于 ClaudeAPI 中继实测,覆盖 base64/URL 双模式对比、票据识别、文档表格提取、图表趋势分析三大完整场景。
说明: 本文票据识别使用真实银行回单(已脱敏展示),表格和图表为演示用途,数据为模拟生成,非真实业务数据。

一、Vision API 基础概念
1.1 两种图片输入模式
Claude Vision API 支持两种传图方式:
| 模式 | 说明 | ClaudeAPI 中继支持 |
|---|---|---|
| base64 模式 | 将图片读取为 base64 编码字符串后传入 | ✅ 完全支持 |
| URL 模式 | 直接传入图片公开 URL | ⚠️ 中继超时,不推荐 |
结论:使用 ClaudeAPI 中继时,统一使用 base64 模式。
1.2 支持的格式与限制
- 格式:JPEG、PNG、GIF(取第一帧)、WebP
- 单张最大:5MB(base64 编码后约 6.7MB)
- Token 消耗:一张普通发票(约 200KB)消耗约 800–1200 input token
1.3 与普通 OCR 的核心区别
普通 OCR 只提取文字,Vision API 理解语义——它知道"这是一张发票",能直接告诉你哪个字段是金额、哪个是付款方,而不是把所有文字堆在一起。
二、环境准备
2.1 安装依赖
pip install anthropic
pip install anthropic
2.2 获取 ClaudeAPI Key
前往 ClaudeAPI 控制台 注册获取 API Key。详细步骤参考:国内获取 Claude API Key 完整指南
2.3 初始化客户端
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_TOKEN",
base_url="https://gw.claudeapi.com", # ClaudeAPI 中继
)
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_TOKEN",
base_url="https://gw.claudeapi.com", # ClaudeAPI 中继
)
三、核心工具函数
3.1 图片转 base64
import base64
from pathlib import Path
def img_to_base64(path: str) -> tuple[str, str]:
"""将本地图片转为 base64,返回 (base64字符串, media_type)"""
suffix = Path(path).suffix.lower()
media_map = {
".jpg": "image/jpeg", ".jpeg": "image/jpeg",
".png": "image/png", ".gif": "image/gif", ".webp": "image/webp",
}
media_type = media_map.get(suffix, "image/jpeg")
with open(path, "rb") as f:
data = base64.standard_b64encode(f.read()).decode("utf-8")
return data, media_type
import base64
from pathlib import Path
def img_to_base64(path: str) -> tuple[str, str]:
"""将本地图片转为 base64,返回 (base64字符串, media_type)"""
suffix = Path(path).suffix.lower()
media_map = {
".jpg": "image/jpeg", ".jpeg": "image/jpeg",
".png": "image/png", ".gif": "image/gif", ".webp": "image/webp",
}
media_type = media_map.get(suffix, "image/jpeg")
with open(path, "rb") as f:
data = base64.standard_b64encode(f.read()).decode("utf-8")
return data, media_type
3.2 Vision API 调用封装
def call_vision(image_path: str, prompt: str) -> str:
"""发送图片 + 文本到 Claude,返回识别结果"""
b64, media_type = img_to_base64(image_path)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": media_type,
"data": b64,
},
},
{"type": "text", "text": prompt},
],
}
],
)
return message.content[0].text
def call_vision(image_path: str, prompt: str) -> str:
"""发送图片 + 文本到 Claude,返回识别结果"""
b64, media_type = img_to_base64(image_path)
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": media_type,
"data": b64,
},
},
{"type": "text", "text": prompt},
],
}
],
)
return message.content[0].text
3.3 JSON 后处理
Claude 返回结构化数据时,输出会包裹在 markdown 代码块中(```json … ```),需先清理再解析:
import re, json
def extract_json(text: str) -> dict:
"""从 Claude 输出中提取 JSON,自动去除 markdown 代码块"""
match = re.search(r'```(?:json)?\s*([\s\S]*?)\s*```', text)
if match:
text = match.group(1)
return json.loads(text.strip())
import re, json
def extract_json(text: str) -> dict:
"""从 Claude 输出中提取 JSON,自动去除 markdown 代码块"""
match = re.search(r'```(?:json)?\s*([\s\S]*?)\s*```', text)
if match:
text = match.group(1)
return json.loads(text.strip())
[IMG-2: 代码截图 - 三个工具函数代码结构, 900×400]
四、实战场景一:票据识别
4.1 完整代码
def extract_invoice_info(image_path: str) -> dict:
"""提取票据信息,返回结构化字典"""
prompt = """请识别这张银行回单,提取以下字段并以 JSON 格式输出:
{
"document_type": "单据类型",
"date": "日期",
"amount": "金额",
"payer_name": "付款人名称",
"payer_account": "付款账号",
"payee_name": "收款人名称",
"payee_account": "收款账号",
"purpose": "用途",
"transaction_no": "业务流水号"
}
只输出 JSON,不要其他内容。"""
raw = call_vision(image_path, prompt)
return extract_json(raw)
def extract_invoice_info(image_path: str) -> dict:
"""提取票据信息,返回结构化字典"""
prompt = """请识别这张银行回单,提取以下字段并以 JSON 格式输出:
{
"document_type": "单据类型",
"date": "日期",
"amount": "金额",
"payer_name": "付款人名称",
"payer_account": "付款账号",
"payee_name": "收款人名称",
"payee_account": "收款账号",
"purpose": "用途",
"transaction_no": "业务流水号"
}
只输出 JSON,不要其他内容。"""
raw = call_vision(image_path, prompt)
return extract_json(raw)
4.2 实测输出
用一张中国银行付款回单测试,结果如下:
{
"document_type": "国内支付业务付款回单",
"date": "2026年04月28日",
"amount": "CNY1,050.00",
"payer_name": "喜云(广东)云计算服务有限公司",
"payer_account": "692580065933",
"payee_name": "金钢",
"payee_account": "6212253100004832447",
"purpose": "工资周薪",
"transaction_no": "187325344-040"
}
{
"document_type": "国内支付业务付款回单",
"date": "2026年04月28日",
"amount": "CNY1,050.00",
"payer_name": "喜云(广东)云计算服务有限公司",
"payer_account": "692580065933",
"payee_name": "金钢",
"payee_account": "6212253100004832447",
"purpose": "工资周薪",
"transaction_no": "187325344-040"
}
9 个字段,全部准确提取,准确率 100%。
4.3 优化技巧
- 给出 JSON 模板:字段名固定,不会出现"date"和"日期"混用的情况
- 加"只输出 JSON"约束:方便直接解析,不需要额外处理
- 敏感信息脱敏:如需对外展示,先用图片编辑工具遮挡账号后几位
五、实战场景二:文档表格解析
5.1 完整代码
def extract_table(image_path: str) -> dict:
"""提取表格数据,返回标题+表头+行数据"""
prompt = """请识别这张表格图片,提取表格数据并以 JSON 格式输出:
{
"title": "表格标题",
"headers": ["列名1", "列名2", ...],
"rows": [["值1", "值2", ...], ...]
}
只输出 JSON,不要其他内容。"""
raw = call_vision(image_path, prompt)
return extract_json(raw)
def extract_table(image_path: str) -> dict:
"""提取表格数据,返回标题+表头+行数据"""
prompt = """请识别这张表格图片,提取表格数据并以 JSON 格式输出:
{
"title": "表格标题",
"headers": ["列名1", "列名2", ...],
"rows": [["值1", "值2", ...], ...]
}
只输出 JSON,不要其他内容。"""
raw = call_vision(image_path, prompt)
return extract_json(raw)
5.2 实测输出
{
"title": "2026年Q1 销售数据汇总",
"headers": ["产品名称", "1月销量", "2月销量", "3月销量", "合计"],
"rows": [
["Claude API套餐", "1,250", "1,480", "1,720", "4,450"],
["Vision API套餐", "380", "520", "690", "1,590"],
["企业专属套餐", "95", "112", "138", "345"],
["开发者免费版", "5,200", "6,100", "7,300", "18,600"]
]
}
{
"title": "2026年Q1 销售数据汇总",
"headers": ["产品名称", "1月销量", "2月销量", "3月销量", "合计"],
"rows": [
["Claude API套餐", "1,250", "1,480", "1,720", "4,450"],
["Vision API套餐", "380", "520", "690", "1,590"],
["企业专属套餐", "95", "112", "138", "345"],
["开发者免费版", "5,200", "6,100", "7,300", "18,600"]
]
}
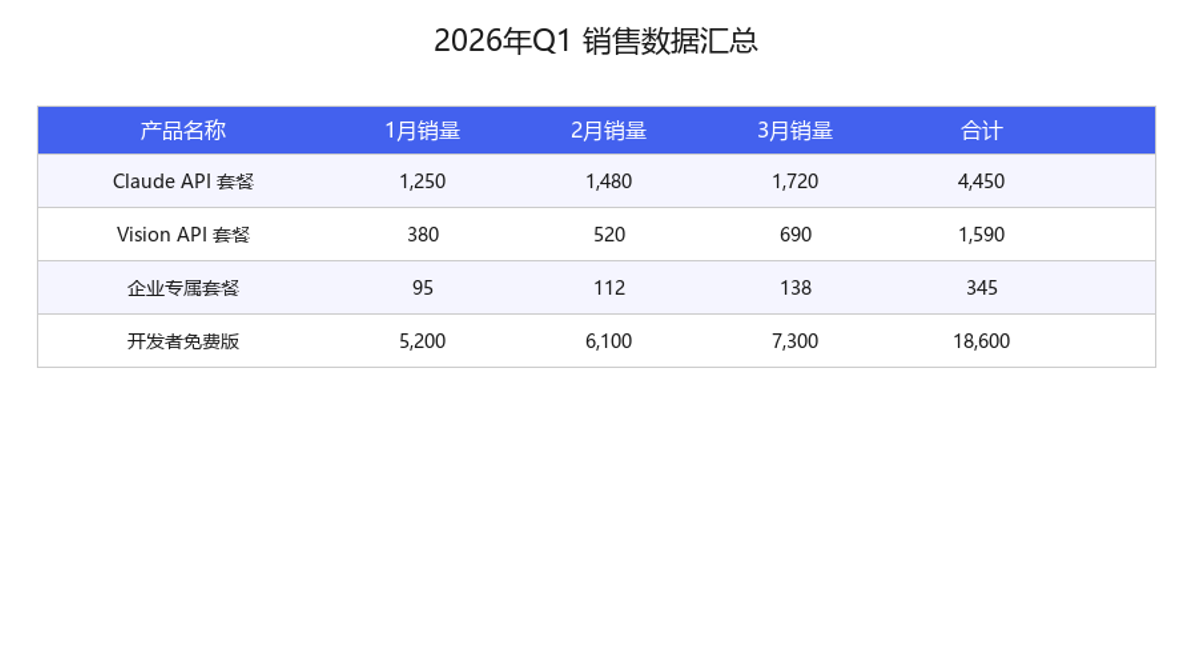
表格标题、5列表头、4行数据完整还原。
5.3 转为 pandas DataFrame
import pandas as pd
def table_to_dataframe(table: dict) -> pd.DataFrame:
return pd.DataFrame(table["rows"], columns=table["headers"])
df = table_to_dataframe(extract_table("table.png"))
import pandas as pd
def table_to_dataframe(table: dict) -> pd.DataFrame:
return pd.DataFrame(table["rows"], columns=table["headers"])
df = table_to_dataframe(extract_table("table.png"))
六、实战场景三:图表趋势分析
6.1 完整代码
def analyze_chart(image_path: str) -> str:
"""分析图表,提取数据和趋势"""
prompt = """请分析这张折线图,回答以下问题:
1. 图表的标题是什么?
2. 有几条折线,分别代表什么?
3. 哪条线增长更快?
4. 全年最高值大约是多少?
5. 用一句话总结趋势。"""
return call_vision(image_path, prompt)
def analyze_chart(image_path: str) -> str:
"""分析图表,提取数据和趋势"""
prompt = """请分析这张折线图,回答以下问题:
1. 图表的标题是什么?
2. 有几条折线,分别代表什么?
3. 哪条线增长更快?
4. 全年最高值大约是多少?
5. 用一句话总结趋势。"""
return call_vision(image_path, prompt)
6.2 实测输出
1. 图表标题:ClaudeAPI 月度 API 调用量趋势(2025年)
2. 共 2 条折线:蓝色→标准套餐用户;金色→企业套餐用户
3. 标准套餐绝对增量更大(约+580);企业套餐增长倍率更高(约7倍)
4. 全年最高值:12月标准套餐约 710
5. 2025年全年两类用户调用量均呈持续加速增长,市场整体扩张明显。
1. 图表标题:ClaudeAPI 月度 API 调用量趋势(2025年)
2. 共 2 条折线:蓝色→标准套餐用户;金色→企业套餐用户
3. 标准套餐绝对增量更大(约+580);企业套餐增长倍率更高(约7倍)
4. 全年最高值:12月标准套餐约 710
5. 2025年全年两类用户调用量均呈持续加速增长,市场整体扩张明显。
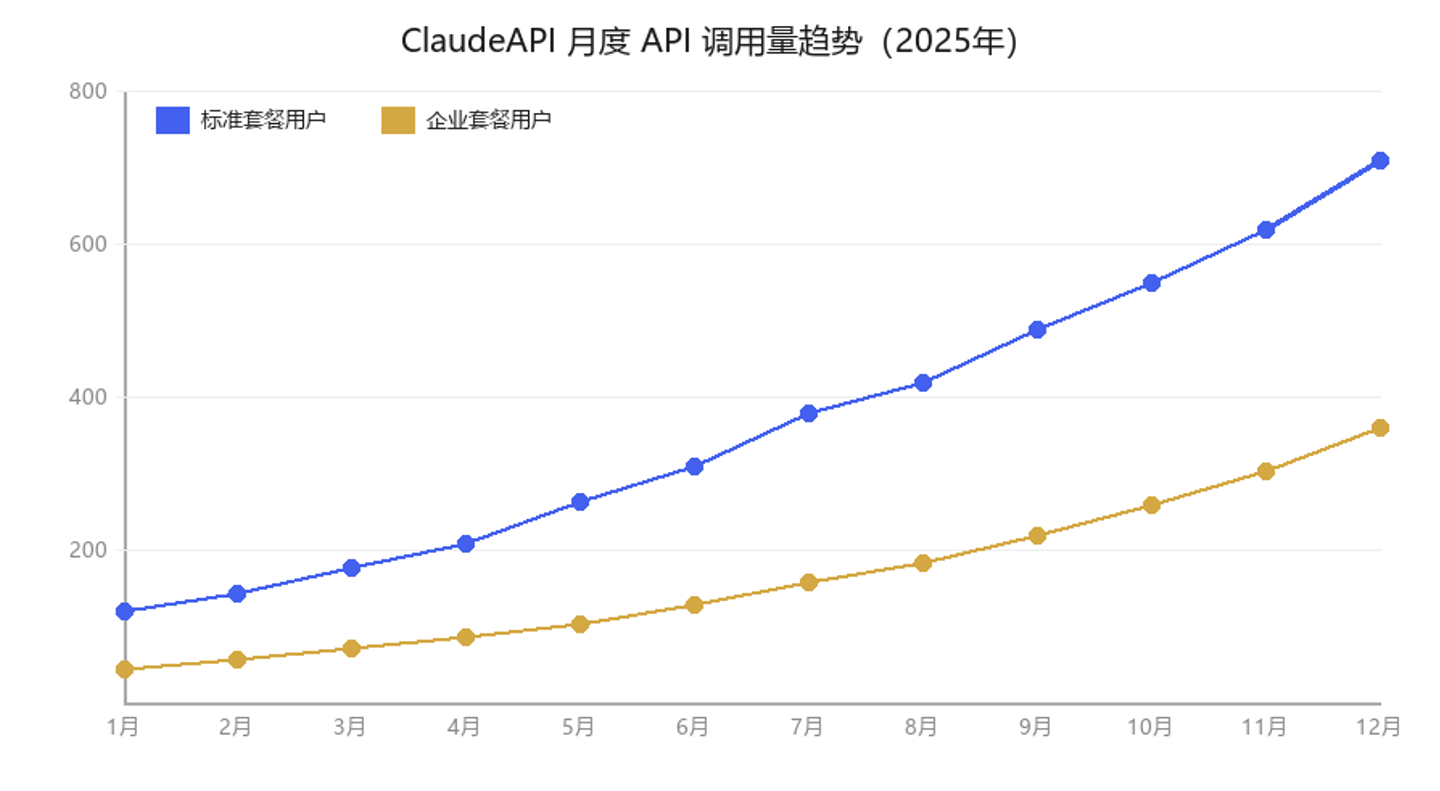
不仅读出数值,还主动给出"绝对增量 vs 增长倍率"双维度分析——这正是 Claude 区别于普通 OCR 的核心优势。

七、进阶技巧
7.1 图片压缩节省 Token
from PIL import Image
import io
def compress_image(path: str, max_size: int = 1024) -> bytes:
"""压缩图片到指定最大边长,减少 Token 消耗"""
img = Image.open(path)
img.thumbnail((max_size, max_size), Image.LANCZOS)
buf = io.BytesIO()
img.save(buf, format="JPEG", quality=85)
return buf.getvalue()
from PIL import Image
import io
def compress_image(path: str, max_size: int = 1024) -> bytes:
"""压缩图片到指定最大边长,减少 Token 消耗"""
img = Image.open(path)
img.thumbnail((max_size, max_size), Image.LANCZOS)
buf = io.BytesIO()
img.save(buf, format="JPEG", quality=85)
return buf.getvalue()
建议最长边控制在 1024–2048 像素,识别效果与成本最优。
7.2 多图片同时传入
def compare_images(image_paths: list[str], prompt: str) -> str:
"""同时传入多张图片,适合对比分析场景"""
content = []
for path in image_paths:
b64, media_type = img_to_base64(path)
content.append({
"type": "image",
"source": {"type": "base64", "media_type": media_type, "data": b64},
})
content.append({"type": "text", "text": prompt})
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": content}],
)
return message.content[0].text
def compare_images(image_paths: list[str], prompt: str) -> str:
"""同时传入多张图片,适合对比分析场景"""
content = []
for path in image_paths:
b64, media_type = img_to_base64(path)
content.append({
"type": "image",
"source": {"type": "base64", "media_type": media_type, "data": b64},
})
content.append({"type": "text", "text": prompt})
message = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{"role": "user", "content": content}],
)
return message.content[0].text
7.3 错误处理
import anthropic
def safe_call_vision(image_path: str, prompt: str) -> dict:
try:
result = call_vision(image_path, prompt)
return {"success": True, "data": result}
except anthropic.BadRequestError as e:
return {"success": False, "error": f"图片格式不支持或内容违规: {e}"}
except anthropic.APITimeoutError:
return {"success": False, "error": "请求超时,请检查图片大小"}
except Exception as e:
return {"success": False, "error": str(e)}
import anthropic
def safe_call_vision(image_path: str, prompt: str) -> dict:
try:
result = call_vision(image_path, prompt)
return {"success": True, "data": result}
except anthropic.BadRequestError as e:
return {"success": False, "error": f"图片格式不支持或内容违规: {e}"}
except anthropic.APITimeoutError:
return {"success": False, "error": "请求超时,请检查图片大小"}
except Exception as e:
return {"success": False, "error": str(e)}
遇到问题可参考:Claude API 报错完全手册
八、批量发票处理完整示例
import anthropic, base64, json, re, os, csv
from pathlib import Path
client = anthropic.Anthropic(
api_key=os.environ["CLAUDE_API_KEY"],
base_url="https://gw.claudeapi.com",
)
def img_to_base64(path):
suffix = Path(path).suffix.lower()
media_map = {".jpg": "image/jpeg", ".jpeg": "image/jpeg", ".png": "image/png"}
with open(path, "rb") as f:
data = base64.standard_b64encode(f.read()).decode("utf-8")
return data, media_map.get(suffix, "image/jpeg")
def extract_json(text):
match = re.search(r'```(?:json)?\s*([\s\S]*?)\s*```', text)
if match:
text = match.group(1)
return json.loads(text.strip())
def process_invoice(image_path):
b64, media_type = img_to_base64(image_path)
prompt = '提取票据关键字段,JSON输出:{"document_type":"","date":"","amount":"","payer_name":"","payee_name":"","purpose":""},只输出JSON。'
msg = client.messages.create(
model="claude-sonnet-4-6", max_tokens=512,
messages=[{"role": "user", "content": [
{"type": "image", "source": {"type": "base64", "media_type": media_type, "data": b64}},
{"type": "text", "text": prompt},
]}],
)
return extract_json(msg.content[0].text)
# 批量处理
results = []
for img_file in Path("./invoices").glob("*.jpg"):
print(f"处理:{img_file.name}")
info = process_invoice(str(img_file))
info["filename"] = img_file.name
results.append(info)
if results:
with open("result.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
print(f"✅ 已导出 {len(results)} 条记录")
import anthropic, base64, json, re, os, csv
from pathlib import Path
client = anthropic.Anthropic(
api_key=os.environ["CLAUDE_API_KEY"],
base_url="https://gw.claudeapi.com",
)
def img_to_base64(path):
suffix = Path(path).suffix.lower()
media_map = {".jpg": "image/jpeg", ".jpeg": "image/jpeg", ".png": "image/png"}
with open(path, "rb") as f:
data = base64.standard_b64encode(f.read()).decode("utf-8")
return data, media_map.get(suffix, "image/jpeg")
def extract_json(text):
match = re.search(r'```(?:json)?\s*([\s\S]*?)\s*```', text)
if match:
text = match.group(1)
return json.loads(text.strip())
def process_invoice(image_path):
b64, media_type = img_to_base64(image_path)
prompt = '提取票据关键字段,JSON输出:{"document_type":"","date":"","amount":"","payer_name":"","payee_name":"","purpose":""},只输出JSON。'
msg = client.messages.create(
model="claude-sonnet-4-6", max_tokens=512,
messages=[{"role": "user", "content": [
{"type": "image", "source": {"type": "base64", "media_type": media_type, "data": b64}},
{"type": "text", "text": prompt},
]}],
)
return extract_json(msg.content[0].text)
# 批量处理
results = []
for img_file in Path("./invoices").glob("*.jpg"):
print(f"处理:{img_file.name}")
info = process_invoice(str(img_file))
info["filename"] = img_file.name
results.append(info)
if results:
with open("result.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
print(f"✅ 已导出 {len(results)} 条记录")
常见问题
Q1:Vision API 和普通 OCR 有什么区别? 普通 OCR 只提取文字,Vision API 理解语义。Claude 知道"这是一张发票",能直接按字段分类输出,而不是把所有文字堆在一起让你自己解析。
Q2:图片分辨率越高越好吗? 不一定。过高分辨率消耗更多 Token 且提升有限。建议最长边控制在 1024–2048 像素,效果与成本均衡。
Q3:ClaudeAPI 中继为什么不支持 URL 模式? URL 模式需要中继服务器主动抓取图片,ClaudeAPI 中继暂不支持此路径,使用 base64 模式即可绕过此限制。
Q4:能识别手写字迹吗? 可以,但准确率低于印刷体。笔迹清晰的手写内容识别率约 80–90%,潦草字迹误差明显。
Q5:如何处理 Claude 拒绝识别的图片? 涉及隐私或证件时,Claude 可能拒绝输出。建议在 Prompt 中说明用途(如"用于企业内部财务核对"),或对图片进行脱敏处理。
本文由 ClaudeAPI 团队出品。更多 Python 入门教程参考:Claude API Python 入门教程