
Claude API Pricing Guide: What It Costs, How It’s Calculated, and How to Save (2026) A lot of developers look at Anthropic’s pricing page and immediately feel lost — token-based billing, separate input/output rates, and no clear answer to the most important question: how much will this actually cost my app at scale?
This guide cuts through the confusion. We’ll break down exactly how Claude API billing works in 2026, give you a practical formula for estimating costs, and share 3 advanced techniques that can cut your API spend by 50% or more.
keywords: Claude API Pricing, Claude APIBilling, Token Calculator, Claude APITop-up, Claude 4.6 Pricing, Prompt Caching
🎯 What You’ll Learn:
- How Claude 4.5/4.6 model pricing works — in plain numbers
- The token-to-word conversion formula so you can estimate costs before you ship
- 3 cost-cutting techniques used by production teams (routing, caching, and more) — slash your bill by 50%+
- How to top up and call the API without dealing with international payment headaches
1.2026 Claude Model Pricing at a Glance
Anthropic uses a pay-as-you-go model — no monthly subscription, no minimum spend. You only pay for what you use.
Pricing is split into two parts: Input (what you send to the model) and Output (what the model generates). Output tokens are priced higher because generating text is computationally more expensive than reading it.
The table below uses USD pricing via Claudeapi.com, which offers direct API access without VPN or international card requirements:
| Model (2026 Lineup) | Best For | Input Price | output Price |
|---|---|---|---|
| Claude 4.6 Sonnet | 🏆 All-around flagship (recommended) complex code generation, multi-step reasoning, long-form writing |
$0.57 / 1M tokens | $2.75 / 1M tokens |
| Claude 4.6 Opus | 🔬 Maximum horsepower top-tier academic analysis, highly complex long-context research tasks |
$2.75 / 1M tokens | $13.75 / 1M tokens |
| Claude 4.5 Haiku | ⚡ Lightweight & fast high-volume customer support, basic data extraction, classification |
¥ 1.00 / 1M tokens | ¥ 5.00 / 1M tokens |
💡 Not sure which model to start with? For most production use cases, Claude 4.6 Sonnet hits the sweet spot between capability and cost. Reserve Opus for tasks that genuinely need it, and use Haiku for anything latency-sensitive or high-volume.
2. What Is a Token — and How Much Text Does 1M Tokens Get You?
“Priced per million tokens” sounds abstract. Let’s make it concrete.
A rough rule of thumb used across the industry:
- 1 English word ≈ 1.2–1.3 tokens
That means 1 million tokens ≈ 700,000–800,000 English words — roughly the length of two full novels. For most production apps, that’s an enormous amount of headroom.
📊Real-World Example: How Much Does It Cost to Generate One Weekly Report?
Say you’ve built an internal tool using *Claude 4.6 Sonnet that auto-generates weekly summaries for your engineering team.
Input (prompt + source material): This week’s commit log and sprint notes — about 600 words → ~780 tokens
Output (generated report): A clean, structured weekly summary — about 500 words → ~650 tokens
Cost breakdown:
Input cost: (780 / 1,000,000) × $0.55 = ~$0.00043 Output cost: (650 / 1,000,000) × $2.75 = ~$0.00179 Total per report: ~$0.0022 (less than a quarter of a cent)
Bottom line: Even if your team generates 100 reports a day, your daily API cost is around $0.22. That’s a fraction of what a single ChatGPT Plus seat costs — and you’re running it at scale with full programmatic control.
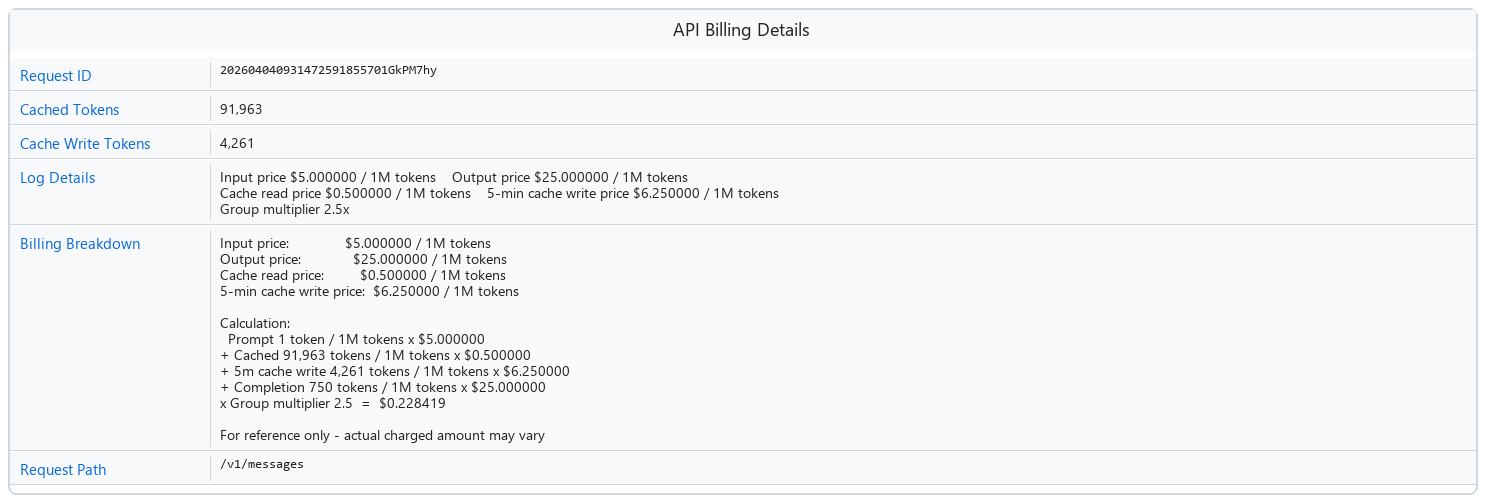
3.3 Pro Techniques to Cut Your Claude API Bill in Half
Even at these low per-token rates, costs can add up fast if your app handles high request volumes or processes large documents. Here are three techniques that production teams actually use:
Technique 1: Use Prompt Caching
This is one of Anthropic’s most powerful — and most underused — cost-saving features.
If your prompts include a large static block of text (a long system prompt, a reference document, a novel’s worth of background lore), you can cache that content server-side. After the first call, Claude doesn’t re-read it from scratch on every request.
-
Without caching: You pay full input price for that block every single time.
-
With caching: Cached input tokens are billed at ~10% of the normal input rate — a 90% cost reduction on that portion. If your system prompt is 10,000 tokens and you’re making 1,000 calls a day, caching alone can save you hundreds of dollars a month.
Technique 2: Dynamic Model Routing (LLM Routing)
Don’t use a sledgehammer to crack a nut.
Route simple tasks to a cheaper model:
Tasks like “does this message contain a phone number?” or “classify this support ticket as urgent/non-urgent” don’t need Sonnet. Send them to Haiku — it’s fast, cheap, and more than capable.
Reserve Sonnet for tasks that need it:
Complex code refactoring, multi-step reasoning, long-form generation — that’s when you call Claude 4.6 Sonnet.
A simple routing layer in your code that dispatches requests based on task complexity can cut your overall API bill by 40–60% without sacrificing output quality.
Technique 3: Truncate Stale Context (Sliding Window)
A common mistake when building chatbots: appending the full conversation history to every single API call. By turn 50, you’re paying for 49 turns of context that’s largely irrelevant to the current question.
Best practice: Keep only the most recent 10–20 turns of core context in your prompt (sliding window). For longer sessions, run a periodic summarization step — every N turns, have the model compress the conversation history into a compact summary and use that instead of the raw transcript.
This alone can reduce your per-session token cost dramatically as conversations grow longer.
4.The Simplest Way to Keep Your API Costs Under Control
For production projects and fast-moving dev teams, your competitive edge comes from shipping better product logic — not from babysitting exchange rates, calculating card fees, or worrying about whether your proxy node is still up.
The cleanest way to eliminate that overhead is to use a dedicated API relay service built for developers. ClaudeAPI.com is designed exactly for this:
-
True pay-as-you-go, zero hidden fees: No virtual card setup, no monthly maintenance fees, no proxy required. Top up directly and start calling the API immediately — even $5 is enough to prototype your MVP.
-
Transparent, per-token billing: Same pricing logic as the official API, with all FX losses eliminated. Every request is logged with exact token usage in your dashboard — you always know exactly what you’re paying for.
-
Zero account ban risk: No account bans to worry about. Your access is stable and your balance is safe.
-
Drop-in integration: No need to change your existing code. Just swap the base_url in your SDK config to ClaudeAPI.com’s endpoint — everything else stays the same.
💰 Start Shipping. Stop Overpaying. In the current AI application boom, the teams that survive and scale are the ones that move fast and keep their unit economics tight.
👉 Sign up at ClaudeAPI.com for free— get your API key instantly and connect the most powerful Claude models to your project in under 5 minutes.
© ClaudeAPI | Pricing last updated April 2026


