
Claude 长 Agent 上下文管理三件套:tool search、context editing、compaction 怎么组合
跑过长链路 Agent 的人都遇到过这个问题:任务还没做完,上下文窗口先满了。工具定义、一轮轮累积的
tool_result块,会一点点把可用上下文吃光。Claude API 提供了三种手段来应对——它们解决的是管线里不同位置的问题,而且可以组合使用。本文讲清每种手段管什么、什么时候上、怎么和 prompt caching 配合不踩坑。

一、问题:上下文是怎么被撑爆的
长 Agent 的上下文消耗来自两块:
- 工具定义:工具越多,每次请求都要带的工具描述越长。
- 累积的 tool_result:一个长 Agent 循环可能产生几百个中间结果,它们当时有用,之后就成了 dead weight,却一直占着上下文。
三种手段在不同位置解决这个问题,它们 compose(可叠加):
| 手段 | 解决什么 | 何时上 |
|---|---|---|
| Tool search | 工具定义占用 | 工具集超过约 20 个,或基线上下文占用开始明显 |
| Context editing | 累积的旧 tool_result | 长循环产生大量中间结果 |
| Compaction | 上下文窗口将满 | 任务跨度超过单个上下文窗口 |
| Prompt caching | 不减 token,但降复算成本 | 工具集大但固定 |
二、Tool search:按需加载工具
当工具集长到一定规模,把全部工具定义塞进每个请求本身就是浪费。Tool search 让模型按需检索要用的工具,而不是一上来就加载全部。
经验阈值:工具集超过约 20 个,或基线上下文占用变得明显时,就该上 tool search。
三、Context editing:清掉失效的 tool_result
一个长 Agent 循环里,早期的工具结果往往在后续步骤已经没用了——比如第 3 步读了个文件,到第 50 步那个内容早已无关。Context editing 把这些已served its purpose 的旧 tool_result 块从历史里移除,不用重启会话就能腾出空间。
关键是它不打断会话连续性:模型继续往下走,只是历史里的死重被清掉了。
四、Compaction:窗口将满时摘要续接
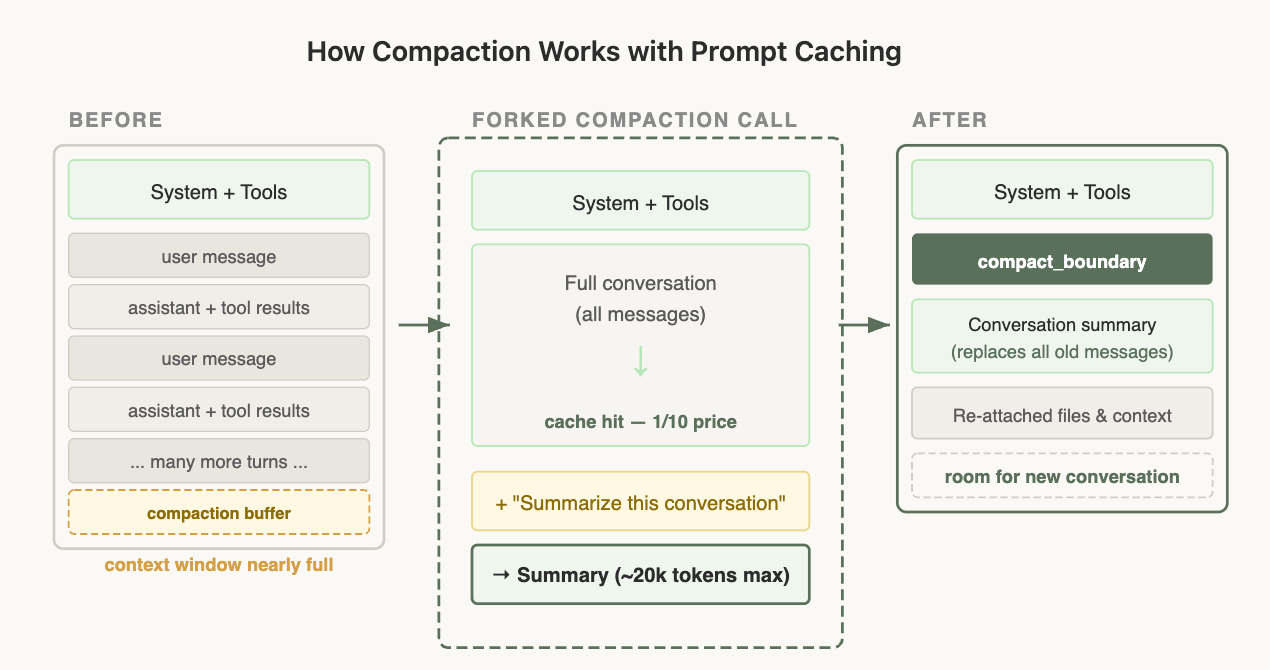
Compaction 是"撞到上下文窗口上限时发生的事":总结目前为止的会话,用摘要开一个新会话继续。
这里有个对缓存至关重要的技巧。做 compaction 时,Claude API 复用与父会话完全相同的系统提示、用户上下文、系统上下文和工具定义:
父会话最后一次请求:
[system prompt][tools][历史消息 1..N]
compaction 后的请求:
[system prompt][tools][历史消息 1..N][compaction prompt]
└─────────── 前缀完全一致 ───────────┘ └─ 唯一的新 token ─┘
父会话最后一次请求:
[system prompt][tools][历史消息 1..N]
compaction 后的请求:
[system prompt][tools][历史消息 1..N][compaction prompt]
└─────────── 前缀完全一致 ───────────┘ └─ 唯一的新 token ─┘
从 API 视角看,这个请求和父会话最后一次请求前缀几乎一样——同样的前缀、同样的工具、同样的历史,所以缓存前缀仍能命中,唯一的新 token 就是 compaction prompt 本身。这是长 Agent 降本的关键:压缩上下文的同时不丢缓存。
五、四者组合:一个长 Agent 的完整配置
把四种手段叠起来,配合 prompt caching,是长 Agent 的推荐配置。claudeapi.com 兼容 Anthropic SDK,仅需替换 base_url:
from anthropic import Anthropic
client = Anthropic(
api_key="sk-...", # claudeapi.com 控制台获取
base_url="https://gw.claudeapi.com", # 平滑接入,仅替换 base_url
)
# 工具定义稳定 → 缓存它,跨成千上万次请求复用前缀
TOOLS = [
# ... 你的工具集 ...
]
# 在最后一个工具上标 cache_control
TOOLS[-1]["cache_control"] = {"type": "ephemeral"}
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "<稳定的系统指令 / 背景知识>",
"cache_control": {"type": "ephemeral"},
}
],
tools=TOOLS,
messages=conversation, # 随循环增长的历史
)
from anthropic import Anthropic
client = Anthropic(
api_key="sk-...", # claudeapi.com 控制台获取
base_url="https://gw.claudeapi.com", # 平滑接入,仅替换 base_url
)
# 工具定义稳定 → 缓存它,跨成千上万次请求复用前缀
TOOLS = [
# ... 你的工具集 ...
]
# 在最后一个工具上标 cache_control
TOOLS[-1]["cache_control"] = {"type": "ephemeral"}
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system=[
{
"type": "text",
"text": "<稳定的系统指令 / 背景知识>",
"cache_control": {"type": "ephemeral"},
}
],
tools=TOOLS,
messages=conversation, # 随循环增长的历史
)
各手段的分工:
- 工具集大但固定 → 靠 prompt caching,缓存一次、复用前缀。它不减 token,但把后续请求的复算成本降到 10%。
- 工具集大且要精简上下文 → 叠加 tool search。
- 循环产生大量中间结果 → 叠加 context editing 清理。
- 任务超出单窗口 → compaction 摘要续接,注意保持前缀一致以命中缓存。
六、保持缓存命中的硬性纪律
上下文管理和 prompt caching 一起用时,缓存命中要求前缀逐字节一致。几条容易翻车的纪律:
| 纪律 | 原因 |
|---|---|
| 绝不在会话中途增删工具 | 工具定义在缓存层级最顶端,一改,后面全部失效 |
| 动态内容(日期/用户 ID)放 user message,别放 system | 系统提示里写死日期会让缓存每天午夜失效 |
| 固定 JSON key 排序 | Go/Swift 等序列化 key 顺序随机,缓存永不命中 |
| 达到 token 下限(Sonnet 4.6 需 ≥4096/检查点) | 不够会被静默跳过,不报错 |
验证缓存是否真命中,看响应里的字段:
print(resp.usage.cache_creation_input_tokens) # 首次写入 > 0
print(resp.usage.cache_read_input_tokens) # 后续命中 > 0
print(resp.usage.cache_creation_input_tokens) # 首次写入 > 0
print(resp.usage.cache_read_input_tokens) # 后续命中 > 0
七、小结
- 长 Agent 上下文管理三件套:tool search(按需加载工具)+ context editing(清失效 tool_result)+ compaction(窗口满时摘要续接),可叠加。
- 配合 prompt caching:工具集大但固定时,缓存前缀复用是最划算的一招。
- compaction 要保持前缀一致才能命中缓存;全程绝不中途改工具集。
模型定价、1M 上下文与 prompt caching 支持详见 claudeapi.com,控制台见 console.claudeapi.com。


