Claude Citations API 实战:让模型自动标注引用来源,RAG 准确率提升 15%
做 RAG(检索增强生成)的工程师都遇到过这种灵魂提问:
“你这个回答到底是从哪段文档里得出来的?”
这个问题之所以致命,是因为模型会自信地引用一段根本不存在的原文。在法律、医疗、金融、合规审计这些场景,引用错了不只是难看,可能直接出事故。
过去大家的解法是在 prompt 里写"请用方括号标注你引用了哪段文字",然后正则解析。这种方式至少有三个问题:
- 模型会编造看似真实但实际不存在的引用编号
- 直接输出原文片段,output token 飙升导致成本翻倍
- 解析逻辑脆弱,模型偶尔不按格式输出就全崩
Anthropic 在 2025 年初推出、2026 年正式 GA 的 Citations API 给出了官方答案——模型直接返回结构化的引用对象,包含字符级偏移、文档索引、原文片段,全部由 API 层保证。
本文给出 Citations 的完整接入方案、三种文档喂入方式、与传统 prompt 引用的对比、以及一个真实可跑的法律 RAG 例子。
一、Citations 到底是什么
Citations 是 Anthropic 在 messages API 上的一个文档块开关。你把文档作为 document content block 传给 Claude,并打开 citations.enabled = true,模型回答时就会自动在每个论点后附带一个citation 对象,结构如下:
{
"type": "char_location",
"cited_text": "...被引用的原文片段...",
"document_index": 0,
"document_title": "annual-report-2025.pdf",
"start_char_index": 1024,
"end_char_index": 1180
}
{
"type": "char_location",
"cited_text": "...被引用的原文片段...",
"document_index": 0,
"document_title": "annual-report-2025.pdf",
"start_char_index": 1024,
"end_char_index": 1180
}
四个关键属性:
| 字段 | 含义 |
|---|---|
cited_text |
被引用的原文片段,不计入 output token |
document_index |
第几个文档(0-indexed) |
start_char_index / end_char_index |
在该文档中的字符偏移 |
type |
引用粒度类型(见下表) |
三种引用粒度
| 粒度 | 适用场景 | 类型字段 |
|---|---|---|
| char_location | 纯文本文档(最精确) | char_location |
| page_location | PDF 文档(页级) | page_location |
| content_block_location | 自定义文档块(最灵活) | content_block_location |
为什么比 prompt 工程更靠谱
Anthropic 自家的对比评测里,Citations 内置版相比 prompt-engineered 版本在召回准确率上提升最高 15%。原因有三个:
- 引用指向是 API 强制保证的——
start_char_index/end_char_index由系统计算,不是模型生成的字符串 cited_text不计入 output token——你不再需要为了让模型"输出原文"而支付额外的 token 费用- 模型不会再编造——所有 citation 都映射到你提供文档的真实位置
二、三种文档喂入方式
方式 1:Plain Text(字符精确引用)
最适合:你已经把文档解析为纯文本,需要字符级精确定位。
import anthropic
client = anthropic.Anthropic(
api_key="sk-你的ClaudeAPI密钥",
base_url="https://gw.claudeapi.com"
)
doc_text = open("contract.txt", "r", encoding="utf-8").read()
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "text",
"media_type": "text/plain",
"data": doc_text,
},
"title": "甲方乙方合作协议-2026.txt",
"citations": {"enabled": True}
},
{
"type": "text",
"text": "这份合同的违约金条款是怎么规定的?"
}
]
}]
)
import anthropic
client = anthropic.Anthropic(
api_key="sk-你的ClaudeAPI密钥",
base_url="https://gw.claudeapi.com"
)
doc_text = open("contract.txt", "r", encoding="utf-8").read()
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "text",
"media_type": "text/plain",
"data": doc_text,
},
"title": "甲方乙方合作协议-2026.txt",
"citations": {"enabled": True}
},
{
"type": "text",
"text": "这份合同的违约金条款是怎么规定的?"
}
]
}]
)
返回结构(精简版):
for block in response.content:
if block.type == "text":
print(block.text)
for cit in block.citations or []:
print(f" └─ 引自 {cit.document_title}")
print(f" 字符 [{cit.start_char_index}:{cit.end_char_index}]")
print(f" 原文:{cit.cited_text[:80]}...")
for block in response.content:
if block.type == "text":
print(block.text)
for cit in block.citations or []:
print(f" └─ 引自 {cit.document_title}")
print(f" 字符 [{cit.start_char_index}:{cit.end_char_index}]")
print(f" 原文:{cit.cited_text[:80]}...")
输出示例:
违约方需向守约方支付合同总金额 20% 的违约金,并在 30 日内一次性支付。
└─ 引自 甲方乙方合作协议-2026.txt
字符 [4128:4280]
原文:第十二条 违约责任:违约方应当向守约方支付合同总金额百分之二十的违约金...
违约方需向守约方支付合同总金额 20% 的违约金,并在 30 日内一次性支付。
└─ 引自 甲方乙方合作协议-2026.txt
字符 [4128:4280]
原文:第十二条 违约责任:违约方应当向守约方支付合同总金额百分之二十的违约金...
方式 2:PDF(页级引用)
最适合:扫描件、含图表的财报、合同原件。模型会自动 OCR + 视觉理解,引用粒度精确到 PDF 的页号。
import base64
with open("annual-report.pdf", "rb") as f:
pdf_b64 = base64.standard_b64encode(f.read()).decode("utf-8")
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_b64,
},
"title": "财报-2025.pdf",
"citations": {"enabled": True}
},
{
"type": "text",
"text": "现金流量表中经营性净现金流是多少?"
}
]
}]
)
import base64
with open("annual-report.pdf", "rb") as f:
pdf_b64 = base64.standard_b64encode(f.read()).decode("utf-8")
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "base64",
"media_type": "application/pdf",
"data": pdf_b64,
},
"title": "财报-2025.pdf",
"citations": {"enabled": True}
},
{
"type": "text",
"text": "现金流量表中经营性净现金流是多少?"
}
]
}]
)
PDF 模式下 citation 会带 start_page_number / end_page_number(1-indexed):
经营性净现金流为 28.5 亿元,同比增长 12%。
└─ 引自 财报-2025.pdf 第 32-32 页
经营性净现金流为 28.5 亿元,同比增长 12%。
└─ 引自 财报-2025.pdf 第 32-32 页
如果文档已经上传到 Files API,可以用 file_id 引用,详见 Files API 完全指南。
方式 3:Custom Content(最灵活,RAG 必选)
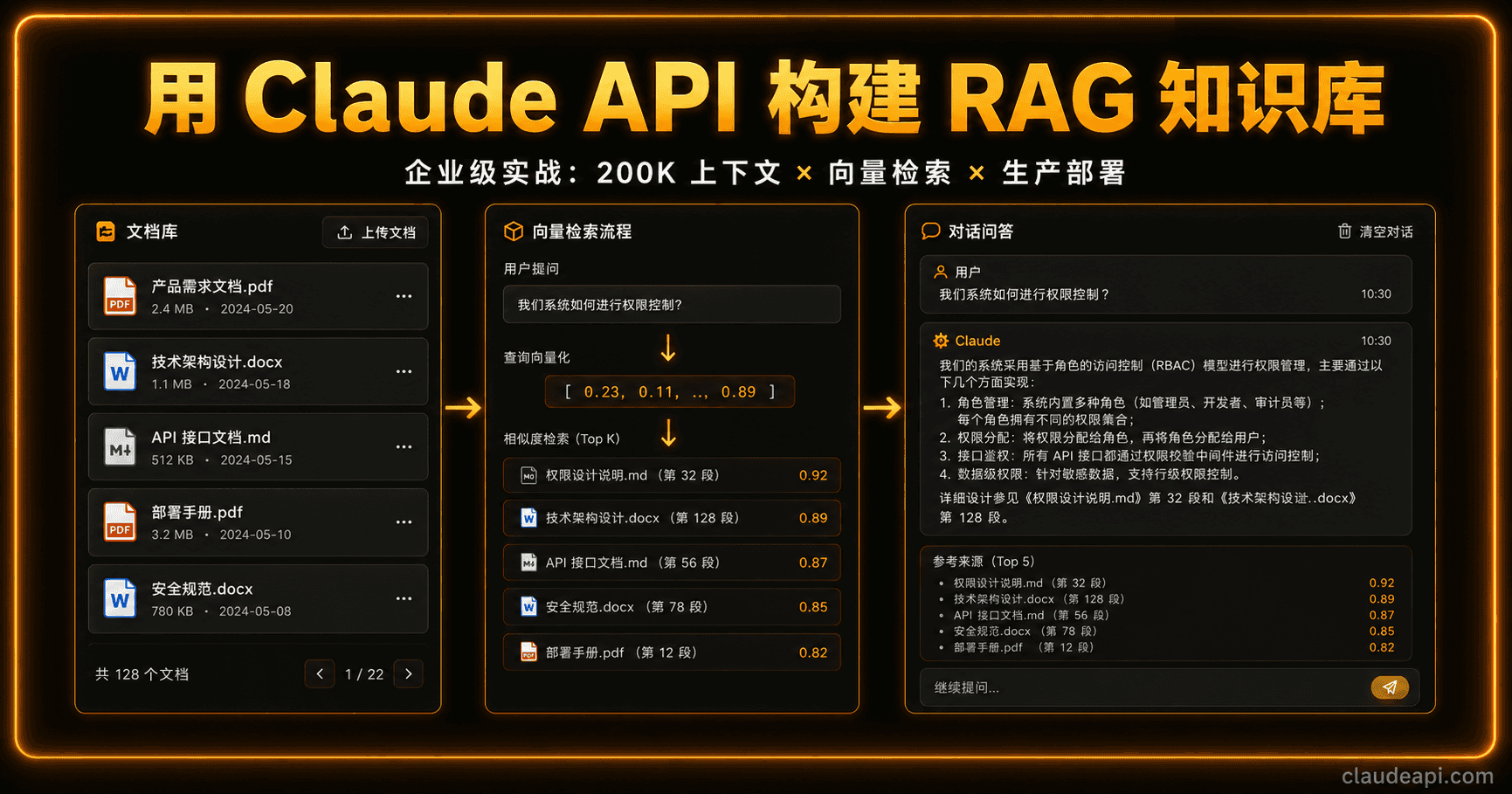
最适合:你自己分了块的 RAG 场景,想精确控制每个 chunk 的边界。
chunks = [
"第一条 本协议由甲方与乙方于 2026 年 1 月 1 日签订...",
"第十二条 违约责任:违约方应当向守约方支付合同总金额百分之二十的违约金...",
"第十五条 争议解决:因本协议产生的任何争议..."
]
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "content",
"content": [
{"type": "text", "text": chunk} for chunk in chunks
]
},
"title": "合同条款-命中片段",
"citations": {"enabled": True}
},
{
"type": "text",
"text": "违约金有多少?争议怎么解决?"
}
]
}]
)
chunks = [
"第一条 本协议由甲方与乙方于 2026 年 1 月 1 日签订...",
"第十二条 违约责任:违约方应当向守约方支付合同总金额百分之二十的违约金...",
"第十五条 争议解决:因本协议产生的任何争议..."
]
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "content",
"content": [
{"type": "text", "text": chunk} for chunk in chunks
]
},
"title": "合同条款-命中片段",
"citations": {"enabled": True}
},
{
"type": "text",
"text": "违约金有多少?争议怎么解决?"
}
]
}]
)
返回的 citation 会带 start_block_index / end_block_index,告诉你引用的是数组里第几块。这种模式特别适合:
- 向量检索后给 top-K 个 chunk:每个 chunk 是一个 block,模型回答时直接告诉你它引用了哪个 block
- 多文档汇总:可以把不同来源的文档片段合并成一个 document,引用结构清晰
三、Node.js / cURL 等价实现
Node.js / TypeScript
import Anthropic from "@anthropic-ai/sdk";
import fs from "fs";
const client = new Anthropic({
apiKey: "sk-你的ClaudeAPI密钥",
baseURL: "https://gw.claudeapi.com",
});
const docText = fs.readFileSync("contract.txt", "utf-8");
const response = await client.messages.create({
model: "claude-opus-4-7",
max_tokens: 1024,
messages: [{
role: "user",
content: [
{
type: "document",
source: { type: "text", media_type: "text/plain", data: docText },
title: "甲方乙方合作协议.txt",
citations: { enabled: true },
},
{ type: "text", text: "违约金条款是?" }
]
}]
});
for (const block of response.content) {
if (block.type === "text") {
console.log(block.text);
for (const cit of (block as any).citations || []) {
console.log(` └─ ${cit.document_title} [${cit.start_char_index}:${cit.end_char_index}]`);
}
}
}
import Anthropic from "@anthropic-ai/sdk";
import fs from "fs";
const client = new Anthropic({
apiKey: "sk-你的ClaudeAPI密钥",
baseURL: "https://gw.claudeapi.com",
});
const docText = fs.readFileSync("contract.txt", "utf-8");
const response = await client.messages.create({
model: "claude-opus-4-7",
max_tokens: 1024,
messages: [{
role: "user",
content: [
{
type: "document",
source: { type: "text", media_type: "text/plain", data: docText },
title: "甲方乙方合作协议.txt",
citations: { enabled: true },
},
{ type: "text", text: "违约金条款是?" }
]
}]
});
for (const block of response.content) {
if (block.type === "text") {
console.log(block.text);
for (const cit of (block as any).citations || []) {
console.log(` └─ ${cit.document_title} [${cit.start_char_index}:${cit.end_char_index}]`);
}
}
}
cURL
curl https://gw.claudeapi.com/v1/messages \
-H "x-api-key: sk-你的ClaudeAPI密钥" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-7",
"max_tokens": 1024,
"messages": [{
"role": "user",
"content": [
{
"type": "document",
"source": {"type": "text", "media_type": "text/plain", "data": "本协议自 2026 年 1 月 1 日生效..."},
"title": "合同.txt",
"citations": {"enabled": true}
},
{"type": "text", "text": "协议什么时候生效?"}
]
}]
}'
curl https://gw.claudeapi.com/v1/messages \
-H "x-api-key: sk-你的ClaudeAPI密钥" \
-H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-7",
"max_tokens": 1024,
"messages": [{
"role": "user",
"content": [
{
"type": "document",
"source": {"type": "text", "media_type": "text/plain", "data": "本协议自 2026 年 1 月 1 日生效..."},
"title": "合同.txt",
"citations": {"enabled": true}
},
{"type": "text", "text": "协议什么时候生效?"}
]
}]
}'
四、Citations vs Prompt 工程引用:六维对比
| 维度 | 传统 Prompt 引用 | Citations API |
|---|---|---|
| 引用可靠性 | 模型可能编造 | API 保证位置真实 |
| Output token 成本 | 引用文本计入输出(昂贵) | cited_text 不计费 |
| 字符级偏移 | 需自己解析 | 内置 start_char_index |
| 多文档支持 | 需要复杂 prompt 描述 | 自动 document_index |
| 实现复杂度 | 自写正则解析 | SDK 直接拿对象 |
| 召回准确率 | 基线 | +15%(Anthropic 内测数据) |
对法律、医疗、金融、政府类客户,这六个维度里前两个就足够说服技术选型。
五、Web Search 自带 Citations(不需要开关)
如果你用的是 Anthropic 原生 web_search 工具(web_search_20260209 是 2026 年的最新版本,支持 dynamic filtering),citations 是默认强开的——你不需要在文档块里加 citations.enabled,每个网页结果都会自带 web_search_result_location 类型的 citation。
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
tools=[{"type": "web_search_20260209", "name": "web_search"}],
messages=[{"role": "user", "content": "2026 年 Anthropic 估值是多少?给出来源。"}]
)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
tools=[{"type": "web_search_20260209", "name": "web_search"}],
messages=[{"role": "user", "content": "2026 年 Anthropic 估值是多少?给出来源。"}]
)
Anthropic 的服务条款明确:直接把 API 输出展示给最终用户时,必须保留 citation 指向原始来源——这条对做搜索/问答类产品的团队尤其重要,别因为美观需求把 url 字段藏起来。
cited_text、title、url 字段同样不计入 token 计费。
六、踩坑清单
坑 1:Citations 与 streaming 一起用要小心累积。 流式返回时,每个 text delta 可能携带 citation_delta,需要在客户端按 block 累积,不能简单拼接字符串。SDK 已封装好,自写客户端要注意。
坑 2:document 必须有 title。 实测不写 title 也能跑通,但所有 citation 的 document_title 字段会为空,前端展示会很难看。养成传 title 的习惯。
坑 3:Custom content 模式下,block 太碎会影响召回。 把一份合同拆成 200 个 8 字 block,模型反而会"看不清"。建议每个 block 保持 100-500 字的语义完整段落,太碎反而降低准确率。
坑 4:不是所有模型都返回引用粒度一致。 Opus 4.7 / Sonnet 4.6 / Haiku 4.5 都支持 Citations,但 Haiku 在多文档复杂场景下偶尔会漏引用。重要场景请用 Opus 4.7 或 Sonnet 4.6。
坑 5:Citations 不等于"防幻觉"。 模型仍然可能误读文档语义。Citations 只保证"引用位置真实存在",不保证"引用解读正确"。生产环境建议二次校验:把 cited_text 和模型回答做语义一致性检查。
坑 6:国内直连 api.anthropic.com 不通。 把 base_url 改成 https://gw.claudeapi.com 即可使用 Citations 全部能力,无需额外配置。
七、一个完整的法律 RAG 端到端示例
把上面的 Custom Content 模式串起来,做一个最小可跑的法律咨询助手:
import anthropic
from typing import List
client = anthropic.Anthropic(
api_key="sk-你的ClaudeAPI密钥",
base_url="https://gw.claudeapi.com"
)
# 假设你有一个向量数据库 (Pinecone / Weaviate / Chroma)
def retrieve_chunks(query: str, k: int = 5) -> List[dict]:
"""返回 top-k 法条片段"""
# ... 你的向量检索代码
return [
{"law": "民法典", "article": "第585条", "text": "当事人可以约定一方违约时..."},
{"law": "合同法", "article": "第114条", "text": "约定的违约金低于造成的损失..."},
# ...
]
def answer_with_citations(question: str):
chunks = retrieve_chunks(question)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
system="你是一个严谨的法律咨询助手。回答必须仅基于提供的法条片段,不允许引用未提供的法律。",
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "content",
"content": [
{"type": "text",
"text": f"【{c['law']} {c['article']}】{c['text']}"}
for c in chunks
]
},
"title": "命中的法律条文",
"citations": {"enabled": True}
},
{"type": "text", "text": question}
]
}]
)
# 结构化输出,附带引用
result = {"answer": "", "citations": []}
for block in response.content:
if block.type == "text":
result["answer"] += block.text
for cit in (block.citations or []):
idx = cit.start_block_index
result["citations"].append({
"law": chunks[idx]["law"],
"article": chunks[idx]["article"],
"cited_text": cit.cited_text,
})
return result
print(answer_with_citations("约定违约金过低能否调整?"))
import anthropic
from typing import List
client = anthropic.Anthropic(
api_key="sk-你的ClaudeAPI密钥",
base_url="https://gw.claudeapi.com"
)
# 假设你有一个向量数据库 (Pinecone / Weaviate / Chroma)
def retrieve_chunks(query: str, k: int = 5) -> List[dict]:
"""返回 top-k 法条片段"""
# ... 你的向量检索代码
return [
{"law": "民法典", "article": "第585条", "text": "当事人可以约定一方违约时..."},
{"law": "合同法", "article": "第114条", "text": "约定的违约金低于造成的损失..."},
# ...
]
def answer_with_citations(question: str):
chunks = retrieve_chunks(question)
response = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
system="你是一个严谨的法律咨询助手。回答必须仅基于提供的法条片段,不允许引用未提供的法律。",
messages=[{
"role": "user",
"content": [
{
"type": "document",
"source": {
"type": "content",
"content": [
{"type": "text",
"text": f"【{c['law']} {c['article']}】{c['text']}"}
for c in chunks
]
},
"title": "命中的法律条文",
"citations": {"enabled": True}
},
{"type": "text", "text": question}
]
}]
)
# 结构化输出,附带引用
result = {"answer": "", "citations": []}
for block in response.content:
if block.type == "text":
result["answer"] += block.text
for cit in (block.citations or []):
idx = cit.start_block_index
result["citations"].append({
"law": chunks[idx]["law"],
"article": chunks[idx]["article"],
"cited_text": cit.cited_text,
})
return result
print(answer_with_citations("约定违约金过低能否调整?"))
输出结构示例:
{
"answer": "根据法律规定,约定违约金低于造成损失的,可以请求法院或仲裁机构予以增加。",
"citations": [
{
"law": "合同法",
"article": "第114条",
"cited_text": "约定的违约金低于造成的损失的,当事人可以请求人民法院或者仲裁机构予以增加..."
}
]
}
{
"answer": "根据法律规定,约定违约金低于造成损失的,可以请求法院或仲裁机构予以增加。",
"citations": [
{
"law": "合同法",
"article": "第114条",
"cited_text": "约定的违约金低于造成的损失的,当事人可以请求人民法院或者仲裁机构予以增加..."
}
]
}
这样的输出可以直接喂给前端做"鼠标悬停展示原文"或者"导出审计报告",工程友好度远超 prompt 工程版本。
八、为什么用 ClaudeAPI.com 跑 Citations
Citations 是 Anthropic API 原生能力,因此你必须用 Anthropic 原生路径——OpenAI 兼容接口(chat/completions)不支持 Citations。
国内开发者通过 claudeapi.com 接入的优势:
| 维度 | 说明 |
|---|---|
| 协议兼容 | 100% 兼容 Anthropic 原生 messages API,Citations、Files、Batch 全部支持 |
| 接入点 | https://gw.claudeapi.com,国内直连,免梯子 |
| 计费 | 人民币结算,支付宝/微信,按 token 量按需付费 |
| 模型 | Citations 推荐的 Opus 4.7 / Sonnet 4.6 同价同步 |
定价参考 claudeapi.com 价格页。RAG 场景常用 Sonnet 4.6(输入 4 元/M,输出 20 元/M),Citations 的 cited_text 不计费这点尤其能省钱。
小结
Citations 是 Anthropic 官方对"防幻觉 + 可审计"需求的标准答案,比 prompt 工程引用更可靠、更省钱、更易工程化:
- 三种粒度:char_location(纯文本)、page_location(PDF)、content_block_location(自定义 chunk)
- 不计费的省钱细节:cited_text 不计入 output token
- 生产建议:重要场景用 Opus 4.7 / Sonnet 4.6,document 一定要传 title,custom block 保持语义完整段落
国内开发者通过 claudeapi.com 把 base_url 改成 https://gw.claudeapi.com 即可使用全部 Citations 能力,注册支付宝充值起步只需几分钟。
参考资料:Citations API 官方文档、Anthropic Citations 发布博客、Web Search Tool。