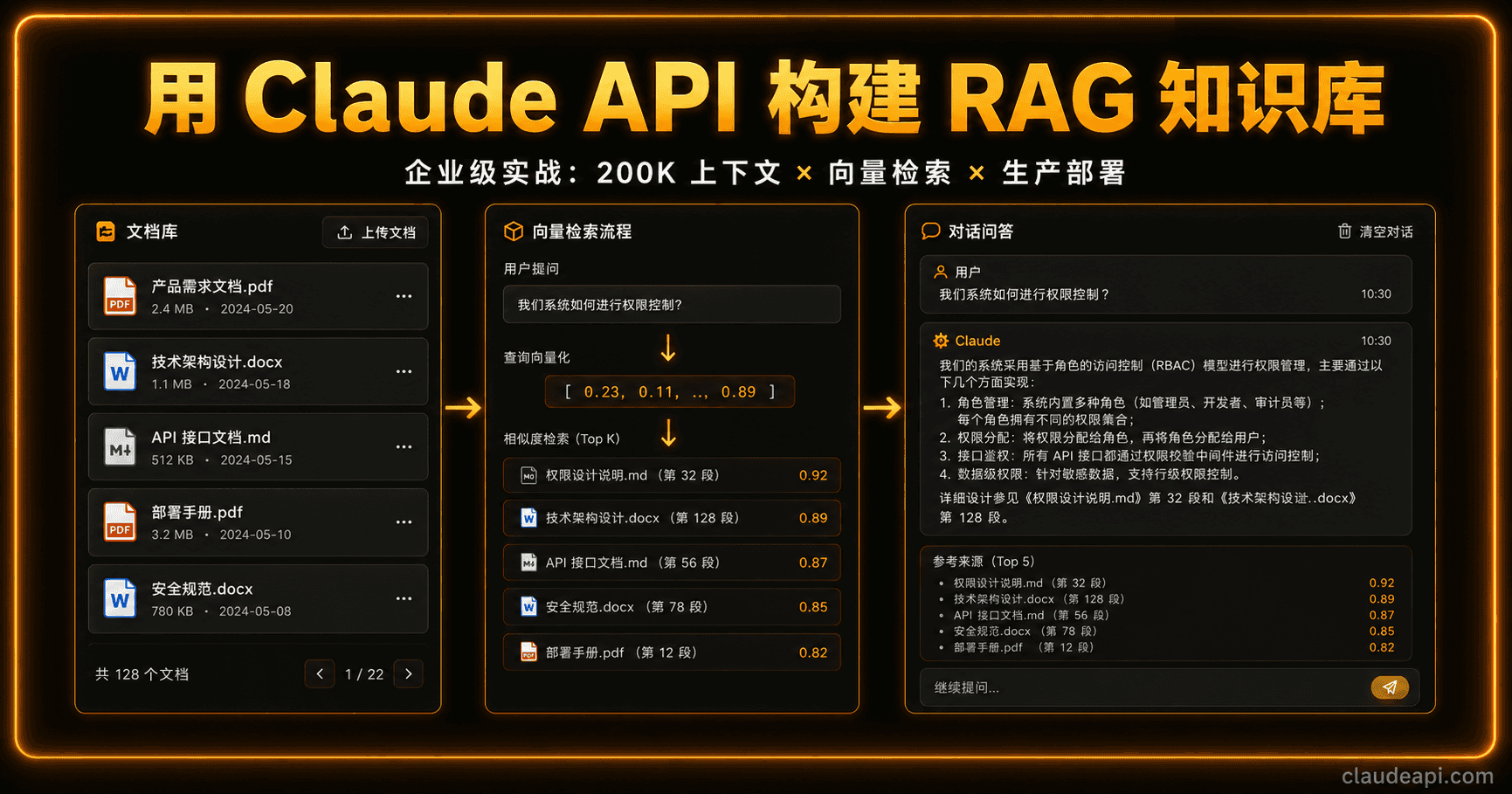
企业内部文档、产品手册、合规政策……这些"死"在 PDF 和 Wiki 里的知识,每年让员工浪费数以千计的小时在重复搜索上。
RAG(Retrieval-Augmented Generation,检索增强生成)是目前最成熟的解决方案。而 Claude API 的 200K Token 超长上下文窗口,让它在 RAG 场景下比其他模型多出一张底牌:当检索到的内容较多时,不需要截断——Claude 能处理相当于一整本中篇小说的上下文。
本文从架构设计到生产部署,完整拆解如何用 Claude API 搭建一套企业级 RAG 问答系统。
为什么企业 RAG 选 Claude?
先说清楚优势,再动手。
| 能力 | Claude Opus 4.6/4.7 | GPT-4o | 说明 |
|---|---|---|---|
| 上下文窗口 | 200K tokens | 128K tokens | Claude 多出 56%,减少截断丢失 |
| 长文档理解 | 极强 | 较强 | Claude 在"大海捞针"测试中表现更稳定 |
| 指令遵循 | 极强 | 强 | 严格按格式输出,适合结构化场景 |
| 中文理解 | 优秀 | 优秀 | 两者相当 |
| API 价格(via ClaudeAPI.com) | Opus: $4/$20 per 1M | — | 性价比可接受 |
对于企业 RAG 场景,Sonnet 4.6($2.4/$12 per 1M tokens)通常已经足够,在 ClaudeAPI.com 注册后可以直接切换。
系统架构总览
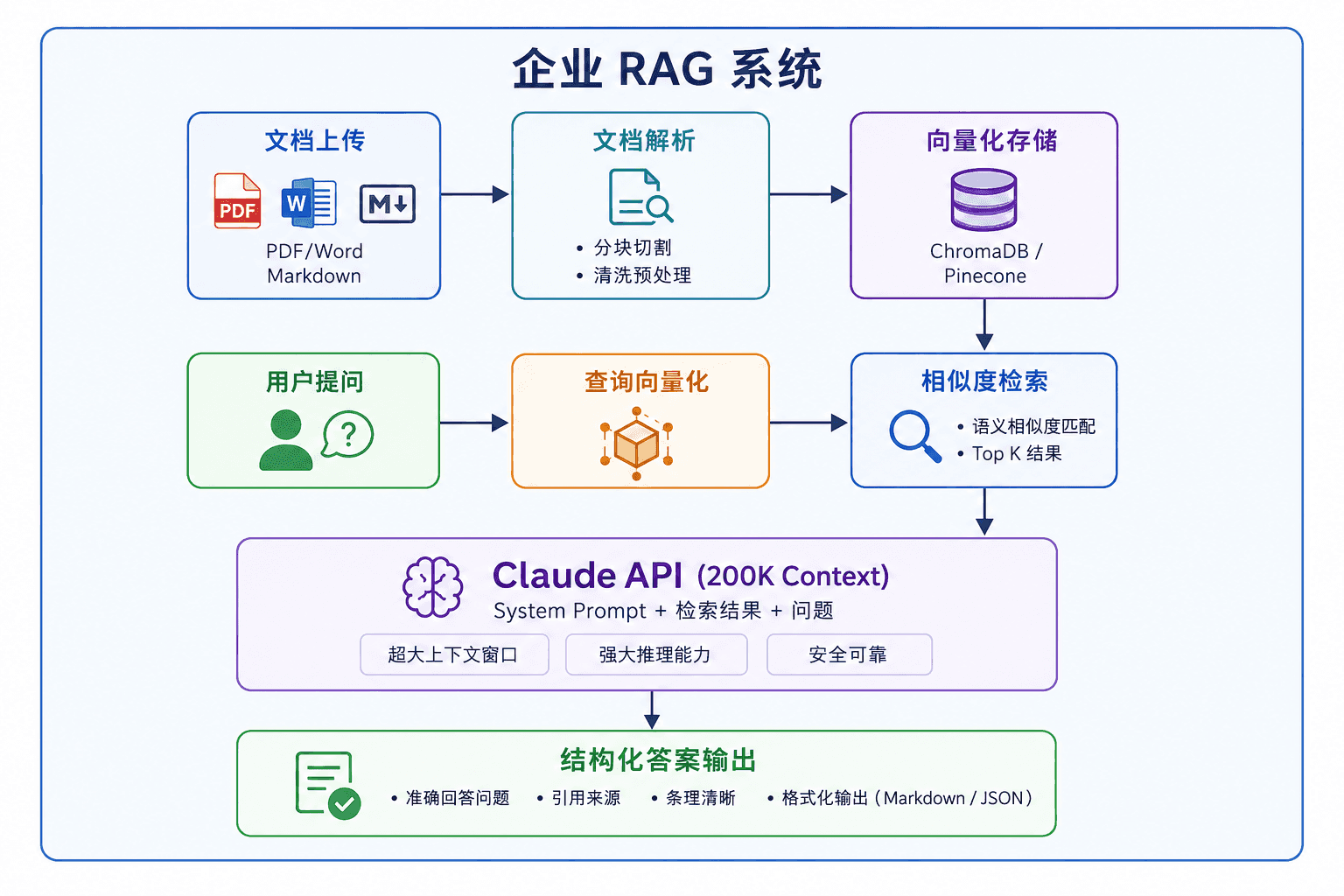
三个核心环节:
- 离线索引:文档解析 → 分块 → 向量化 → 存入向量数据库
- 在线检索:用户问题向量化 → 相似度检索 → 召回 Top-K 文档块
- 生成回答:将检索结果 + 问题注入 Claude,生成有来源引用的答案
---
## 环境准备
```bash
pip install anthropic chromadb sentence-transformers pypdf langchain-text-splitters
---
## 环境准备
```bash
pip install anthropic chromadb sentence-transformers pypdf langchain-text-splitters
API 密钥配置(使用 ClaudeAPI.com 中转,无需翻墙):
import os
os.environ["ANTHROPIC_API_KEY"] = "your-api-key"
os.environ["ANTHROPIC_BASE_URL"] = "https://gw.claudeapi.com"
import os
os.environ["ANTHROPIC_API_KEY"] = "your-api-key"
os.environ["ANTHROPIC_BASE_URL"] = "https://gw.claudeapi.com"
第一步:文档解析与分块
文档分块策略直接影响检索质量,这是很多教程略过的关键细节。
from langchain_text_splitters import RecursiveCharacterTextSplitter
from pypdf import PdfReader
import re
def parse_pdf(file_path: str) -> str:
"""提取 PDF 文本,保留基本结构"""
reader = PdfReader(file_path)
pages = []
for i, page in enumerate(reader.pages):
text = page.extract_text()
if text.strip():
# 标注页码,便于后续引用
pages.append(f"[第{i+1}页]\n{text}")
return "\n\n".join(pages)
def chunk_document(text: str, chunk_size: int = 800, chunk_overlap: int = 150):
"""
分块策略说明:
- chunk_size=800:约 400-600 中文字,一个完整语义段落
- chunk_overlap=150:相邻块有重叠,防止答案被切断
- 按段落/换行优先切分,而非机械按字数
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", ";", ",", " ", ""],
)
chunks = splitter.split_text(text)
return chunks
# 使用示例
raw_text = parse_pdf("company_policy.pdf")
chunks = chunk_document(raw_text)
print(f"文档共分为 {len(chunks)} 个块")
# 文档共分为 47 个块
from langchain_text_splitters import RecursiveCharacterTextSplitter
from pypdf import PdfReader
import re
def parse_pdf(file_path: str) -> str:
"""提取 PDF 文本,保留基本结构"""
reader = PdfReader(file_path)
pages = []
for i, page in enumerate(reader.pages):
text = page.extract_text()
if text.strip():
# 标注页码,便于后续引用
pages.append(f"[第{i+1}页]\n{text}")
return "\n\n".join(pages)
def chunk_document(text: str, chunk_size: int = 800, chunk_overlap: int = 150):
"""
分块策略说明:
- chunk_size=800:约 400-600 中文字,一个完整语义段落
- chunk_overlap=150:相邻块有重叠,防止答案被切断
- 按段落/换行优先切分,而非机械按字数
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", "。", ";", ",", " ", ""],
)
chunks = splitter.split_text(text)
return chunks
# 使用示例
raw_text = parse_pdf("company_policy.pdf")
chunks = chunk_document(raw_text)
print(f"文档共分为 {len(chunks)} 个块")
# 文档共分为 47 个块
企业实践建议:对于表格密集的财务报告,优先考虑用专门的表格解析库(如 camelot)单独处理表格部分,避免向量语义失真。
第二步:向量化与存储
from sentence_transformers import SentenceTransformer
import chromadb
from chromadb.config import Settings
# 推荐中文向量模型:BAAI/bge-large-zh-v1.5
# 英文或中英混合:BAAI/bge-m3(多语言)
embedding_model = SentenceTransformer("BAAI/bge-large-zh-v1.5")
# 初始化 ChromaDB(本地持久化)
chroma_client = chromadb.PersistentClient(path="./knowledge_base_db")
collection = chroma_client.get_or_create_collection(
name="company_docs",
metadata={"hnsw:space": "cosine"} # 余弦相似度
)
def index_documents(chunks: list[str], doc_name: str):
"""将文档块向量化并存入数据库"""
embeddings = embedding_model.encode(chunks, show_progress_bar=True).tolist()
collection.add(
documents=chunks,
embeddings=embeddings,
ids=[f"{doc_name}_chunk_{i}" for i in range(len(chunks))],
metadatas=[{"source": doc_name, "chunk_index": i} for i in range(len(chunks))]
)
print(f"已索引 {len(chunks)} 个文档块,来源:{doc_name}")
# 索引文档
index_documents(chunks, "公司合规政策2026")
from sentence_transformers import SentenceTransformer
import chromadb
from chromadb.config import Settings
# 推荐中文向量模型:BAAI/bge-large-zh-v1.5
# 英文或中英混合:BAAI/bge-m3(多语言)
embedding_model = SentenceTransformer("BAAI/bge-large-zh-v1.5")
# 初始化 ChromaDB(本地持久化)
chroma_client = chromadb.PersistentClient(path="./knowledge_base_db")
collection = chroma_client.get_or_create_collection(
name="company_docs",
metadata={"hnsw:space": "cosine"} # 余弦相似度
)
def index_documents(chunks: list[str], doc_name: str):
"""将文档块向量化并存入数据库"""
embeddings = embedding_model.encode(chunks, show_progress_bar=True).tolist()
collection.add(
documents=chunks,
embeddings=embeddings,
ids=[f"{doc_name}_chunk_{i}" for i in range(len(chunks))],
metadatas=[{"source": doc_name, "chunk_index": i} for i in range(len(chunks))]
)
print(f"已索引 {len(chunks)} 个文档块,来源:{doc_name}")
# 索引文档
index_documents(chunks, "公司合规政策2026")
第三步:检索 + Claude 生成答案
这是整个系统的核心。Prompt 工程决定了答案质量的上限。
import anthropic
client = anthropic.Anthropic(
api_key=os.environ["ANTHROPIC_API_KEY"],
base_url=os.environ["ANTHROPIC_BASE_URL"],
)
def retrieve(query: str, top_k: int = 5) -> list[dict]:
"""检索最相关的文档块"""
query_embedding = embedding_model.encode([query]).tolist()
results = collection.query(
query_embeddings=query_embedding,
n_results=top_k,
include=["documents", "metadatas", "distances"]
)
retrieved = []
for doc, meta, dist in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
# 距离转相似度,过滤低质量结果
similarity = 1 - dist
if similarity > 0.4: # 相似度阈值,可调整
retrieved.append({
"content": doc,
"source": meta["source"],
"chunk_index": meta["chunk_index"],
"similarity": round(similarity, 3)
})
return retrieved
def build_context(retrieved_chunks: list[dict]) -> str:
"""将检索结果格式化为 Claude 可读的上下文"""
if not retrieved_chunks:
return "未找到相关文档。"
context_parts = []
for i, chunk in enumerate(retrieved_chunks, 1):
context_parts.append(
f"【参考文档 {i}】来源:{chunk['source']}(相关度:{chunk['similarity']})\n"
f"{chunk['content']}"
)
return "\n\n---\n\n".join(context_parts)
SYSTEM_PROMPT = """你是一名企业知识库助手,基于提供的参考文档回答员工问题。
回答规则:
1. 只基于"参考文档"中的信息回答,不要编造或补充文档中没有的内容
2. 如果参考文档中没有相关信息,直接说"文档中未找到相关信息,建议咨询相关部门"
3. 回答时标注信息来源,例如:(来源:公司合规政策2026)
4. 使用清晰的结构化格式,重要信息用加粗标注
5. 回答简洁专业,避免冗余"""
def answer_question(question: str) -> dict:
"""完整的 RAG 问答流程"""
# 1. 检索
retrieved = retrieve(question, top_k=5)
context = build_context(retrieved)
# 2. 构建消息
user_message = f"""参考文档:
{context}
---
员工问题:{question}"""
# 3. 调用 Claude
response = client.messages.create(
model="claude-sonnet-4-6", # 企业场景推荐 Sonnet,性价比最优
max_tokens=1500,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": user_message}]
)
answer = response.content[0].text
return {
"question": question,
"answer": answer,
"sources": list(set(c["source"] for c in retrieved)),
"retrieved_count": len(retrieved),
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens,
}
# 测试
result = answer_question("员工出差报销餐费的上限是多少?")
print(result["answer"])
print(f"\n📚 来源:{result['sources']}")
print(f"💰 消耗:{result['input_tokens']} 输入 + {result['output_tokens']} 输出 tokens")
import anthropic
client = anthropic.Anthropic(
api_key=os.environ["ANTHROPIC_API_KEY"],
base_url=os.environ["ANTHROPIC_BASE_URL"],
)
def retrieve(query: str, top_k: int = 5) -> list[dict]:
"""检索最相关的文档块"""
query_embedding = embedding_model.encode([query]).tolist()
results = collection.query(
query_embeddings=query_embedding,
n_results=top_k,
include=["documents", "metadatas", "distances"]
)
retrieved = []
for doc, meta, dist in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
# 距离转相似度,过滤低质量结果
similarity = 1 - dist
if similarity > 0.4: # 相似度阈值,可调整
retrieved.append({
"content": doc,
"source": meta["source"],
"chunk_index": meta["chunk_index"],
"similarity": round(similarity, 3)
})
return retrieved
def build_context(retrieved_chunks: list[dict]) -> str:
"""将检索结果格式化为 Claude 可读的上下文"""
if not retrieved_chunks:
return "未找到相关文档。"
context_parts = []
for i, chunk in enumerate(retrieved_chunks, 1):
context_parts.append(
f"【参考文档 {i}】来源:{chunk['source']}(相关度:{chunk['similarity']})\n"
f"{chunk['content']}"
)
return "\n\n---\n\n".join(context_parts)
SYSTEM_PROMPT = """你是一名企业知识库助手,基于提供的参考文档回答员工问题。
回答规则:
1. 只基于"参考文档"中的信息回答,不要编造或补充文档中没有的内容
2. 如果参考文档中没有相关信息,直接说"文档中未找到相关信息,建议咨询相关部门"
3. 回答时标注信息来源,例如:(来源:公司合规政策2026)
4. 使用清晰的结构化格式,重要信息用加粗标注
5. 回答简洁专业,避免冗余"""
def answer_question(question: str) -> dict:
"""完整的 RAG 问答流程"""
# 1. 检索
retrieved = retrieve(question, top_k=5)
context = build_context(retrieved)
# 2. 构建消息
user_message = f"""参考文档:
{context}
---
员工问题:{question}"""
# 3. 调用 Claude
response = client.messages.create(
model="claude-sonnet-4-6", # 企业场景推荐 Sonnet,性价比最优
max_tokens=1500,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": user_message}]
)
answer = response.content[0].text
return {
"question": question,
"answer": answer,
"sources": list(set(c["source"] for c in retrieved)),
"retrieved_count": len(retrieved),
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens,
}
# 测试
result = answer_question("员工出差报销餐费的上限是多少?")
print(result["answer"])
print(f"\n📚 来源:{result['sources']}")
print(f"💰 消耗:{result['input_tokens']} 输入 + {result['output_tokens']} 输出 tokens")
第四步:多轮对话支持
真实企业场景中,员工往往会追问。加入对话历史管理:
class RAGChatSession:
def __init__(self, max_history: int = 6):
self.history = []
self.max_history = max_history # 保留最近 N 轮,控制 token 消耗
def chat(self, question: str) -> str:
retrieved = retrieve(question, top_k=4)
context = build_context(retrieved)
# 当前轮的用户消息
current_message = f"参考文档:\n{context}\n\n---\n\n问题:{question}"
messages = self.history + [{"role": "user", "content": current_message}]
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
system=SYSTEM_PROMPT,
messages=messages
)
answer = response.content[0].text
# 更新历史(只保存问题和答案,不保存 context 以节省 token)
self.history.append({"role": "user", "content": question})
self.history.append({"role": "assistant", "content": answer})
# 截断过长历史
if len(self.history) > self.max_history * 2:
self.history = self.history[-(self.max_history * 2):]
return answer
# 使用示例
session = RAGChatSession()
print(session.chat("出差住宿标准是什么?"))
print(session.chat("北京的标准和上海一样吗?")) # 追问,模型理解上下文
class RAGChatSession:
def __init__(self, max_history: int = 6):
self.history = []
self.max_history = max_history # 保留最近 N 轮,控制 token 消耗
def chat(self, question: str) -> str:
retrieved = retrieve(question, top_k=4)
context = build_context(retrieved)
# 当前轮的用户消息
current_message = f"参考文档:\n{context}\n\n---\n\n问题:{question}"
messages = self.history + [{"role": "user", "content": current_message}]
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
system=SYSTEM_PROMPT,
messages=messages
)
answer = response.content[0].text
# 更新历史(只保存问题和答案,不保存 context 以节省 token)
self.history.append({"role": "user", "content": question})
self.history.append({"role": "assistant", "content": answer})
# 截断过长历史
if len(self.history) > self.max_history * 2:
self.history = self.history[-(self.max_history * 2):]
return answer
# 使用示例
session = RAGChatSession()
print(session.chat("出差住宿标准是什么?"))
print(session.chat("北京的标准和上海一样吗?")) # 追问,模型理解上下文
第五步:生产环境优化
5.1 Prompt Caching——大幅降低成本
当 System Prompt 较长(如包含企业制度摘要)时,启用 Prompt Caching 可节省 90% 的 System Prompt token 费用:
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
system=[
{
"type": "text",
"text": SYSTEM_PROMPT + "\n\n" + COMPANY_BACKGROUND, # 固定的长文本
"cache_control": {"type": "ephemeral"} # 开启缓存
}
],
messages=messages
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1500,
system=[
{
"type": "text",
"text": SYSTEM_PROMPT + "\n\n" + COMPANY_BACKGROUND, # 固定的长文本
"cache_control": {"type": "ephemeral"} # 开启缓存
}
],
messages=messages
)
成本测算示例:假设 System Prompt = 2000 tokens,每天 1000 次查询:
- 不开缓存:2000 × 1000 × $2.4/1M = $4.8/天
- 开启缓存(命中率 95%):约 $0.5/天,节省 90%
5.2 混合检索——提升召回率
纯向量检索有时会漏掉关键词精确匹配的结果。结合 BM25 关键词检索效果更好:
from rank_bm25 import BM25Okapi
import jieba
class HybridRetriever:
def __init__(self, chunks: list[str]):
self.chunks = chunks
# BM25 索引
tokenized = [list(jieba.cut(c)) for c in chunks]
self.bm25 = BM25Okapi(tokenized)
def retrieve(self, query: str, top_k: int = 5) -> list[str]:
# 向量检索结果
vec_results = retrieve(query, top_k=top_k * 2)
vec_ids = {c["chunk_index"]: c["similarity"] for c in vec_results}
# BM25 检索结果
query_tokens = list(jieba.cut(query))
bm25_scores = self.bm25.get_scores(query_tokens)
bm25_top = sorted(enumerate(bm25_scores), key=lambda x: x[1], reverse=True)[:top_k * 2]
# RRF 融合排序(Reciprocal Rank Fusion)
rrf_scores = {}
for rank, (idx, _) in enumerate(bm25_top):
rrf_scores[idx] = rrf_scores.get(idx, 0) + 1 / (60 + rank + 1)
for rank, (idx, _) in enumerate(sorted(vec_ids.items(), key=lambda x: x[1], reverse=True)):
rrf_scores[idx] = rrf_scores.get(idx, 0) + 1 / (60 + rank + 1)
top_indices = sorted(rrf_scores, key=rrf_scores.get, reverse=True)[:top_k]
return [self.chunks[i] for i in top_indices]
from rank_bm25 import BM25Okapi
import jieba
class HybridRetriever:
def __init__(self, chunks: list[str]):
self.chunks = chunks
# BM25 索引
tokenized = [list(jieba.cut(c)) for c in chunks]
self.bm25 = BM25Okapi(tokenized)
def retrieve(self, query: str, top_k: int = 5) -> list[str]:
# 向量检索结果
vec_results = retrieve(query, top_k=top_k * 2)
vec_ids = {c["chunk_index"]: c["similarity"] for c in vec_results}
# BM25 检索结果
query_tokens = list(jieba.cut(query))
bm25_scores = self.bm25.get_scores(query_tokens)
bm25_top = sorted(enumerate(bm25_scores), key=lambda x: x[1], reverse=True)[:top_k * 2]
# RRF 融合排序(Reciprocal Rank Fusion)
rrf_scores = {}
for rank, (idx, _) in enumerate(bm25_top):
rrf_scores[idx] = rrf_scores.get(idx, 0) + 1 / (60 + rank + 1)
for rank, (idx, _) in enumerate(sorted(vec_ids.items(), key=lambda x: x[1], reverse=True)):
rrf_scores[idx] = rrf_scores.get(idx, 0) + 1 / (60 + rank + 1)
top_indices = sorted(rrf_scores, key=rrf_scores.get, reverse=True)[:top_k]
return [self.chunks[i] for i in top_indices]
5.3 流式输出——提升用户体验
对于较长的答案,流式输出让用户不必等待:
def answer_stream(question: str):
retrieved = retrieve(question)
context = build_context(retrieved)
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1500,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": f"参考文档:\n{context}\n\n问题:{question}"}]
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True) # 或推送到前端 SSE
def answer_stream(question: str):
retrieved = retrieve(question)
context = build_context(retrieved)
with client.messages.stream(
model="claude-sonnet-4-6",
max_tokens=1500,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": f"参考文档:\n{context}\n\n问题:{question}"}]
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True) # 或推送到前端 SSE
成本与性能基准参考
基于 ClaudeAPI.com 的 Sonnet 4.6 定价,估算一个中型企业知识库(10万文档块,日均 500 次问答)的月度成本:
| 项目 | 估算 |
|---|---|
| 向量化(一次性) | BGE 模型本地运行,接近免费 |
| 每次问答均摊 input tokens | ~3000 tokens(检索结果 + 历史) |
| 每次问答均摊 output tokens | ~500 tokens |
| 月度 API 费用(500次/天) | 约 $65-80/月 |
| 开启 Prompt Caching 后 | 约 $30-40/月(节省约 50%) |
这个成本对于企业来说完全可接受,而它替代的是每月数十万的人力重复答疑成本。
快速开始清单
- [ ] 在 ClaudeAPI.com 注册并获取 API Key
- [ ] 配置
ANTHROPIC_BASE_URL=https://gw.claudeapi.com - [ ] 安装依赖:
pip install anthropic chromadb sentence-transformers - [ ] 下载中文向量模型:
BAAI/bge-large-zh-v1.5 - [ ] 将企业文档 PDF/Word 放入待处理目录
- [ ] 运行索引脚本,完成向量化
- [ ] 启动问答接口,开始测试
总结
Claude API 在 RAG 场景下的核心优势:200K 超长上下文让检索结果可以更充分地喂给模型,不必因为担心上下文溢出而激进地截断文档,答案质量更稳定。
完整的企业 RAG 系统关键决策点:
- 分块策略影响检索召回质量,800 tokens + 150 重叠是个好起点
- 混合检索(向量 + BM25)比纯向量更稳健
- Prompt Caching 在固定 System Prompt 场景下可节省 50-90% 成本
- 模型选择:Sonnet 4.6 是企业 RAG 的性价比之选,Opus 适合合规/法律等高精度场景
ClaudeAPI.com 提供 Claude 官方同款 API,无需额外网络配置,只需将
base_url指向https://gw.claudeapi.com即可开始构建。


